

Supervised learning (Επιβλεπόμενη Μάθηση): Ορισμός και Παραδείγματα
Το Machine Learning (μηχανική μάθηση) και η Τεχνητή Νοημοσύνη κάνουν καθημερινά τη ζωή μας πιο εύκολη, προσφέροντας πολλαπλά οφέλη και πρόσφορο έδαφος για καινοτομία και αλλαγή. Ειδικότερα, η μηχανική μάθηση, ως υποσύνολο της τεχνητής νοημοσύνης, περιλαμβάνει αλγορίθμους που μαθαίνουν από δεδομένα για να κάνουν προβλέψεις και αποφάσεις, ενισχύοντας σημαντικά τον τομέα της επιστήμης δεδομένων με εφαρμογές στη στατιστική υπολογιστική, την εξόρυξη δεδομένων, και τη δημιουργία περίπλοκων μοντέλων και αλγορίθμων για την ανάλυση ιστορικών σχέσεων και τάσεων μέσα στα δεδομένα. Ο όγκος των δεδομένων ως γνωστόν είναι τεράστιος, με αποτέλεσμα να αναδύονται διαρκώς νέες μέθοδοι και τεχνικές αποτελεσματικής εκπαίδευσης μηχανών σε μεγάλα σύνολα δεδομένων.
Μια πολύ γνωστή μέθοδος και υποκατηγορία μηχανικής μάθησης είναι η επιβλεπόμενη μάθηση, στην οποία θα αναφερθούμε αναλυτικά παρακάτω:
Τι είναι το supervised learning και πώς λειτουργεί
Ποιοι τύποι αλγορίθμων supervised learning υπάρχουν
Ποιες οι διαφορές με την unsupervised learning (μη-επιβλεπόμενη) μάθηση
Μερικά βασικά παραδείγματα supervised learning
Ας ξεκινήσουμε με ένα βασικό ορισμό.
Τι Είναι η Επιβλεπόμενη Μάθηση;
H επιβλεπόμενη μάθηση (supervised learning) είναι μια υποκατηγορία της μηχανικής μάθησης όπου τα μοντέλα ή, αλλιώς, ο αλγόριθμος εκπαιδεύεται σε ένα επισημασμένο σύνολο δεδομένων (labeled dataset).
Τα επισημασμένα σύνολα δεδομένων χρησιμοποιούνται για την εκπαίδευση αλγορίθμων που ταξινομούν δεδομένα ή κάνουν προβλέψεις με μεγάλη ακρίβεια. Τα “επισημασμένα” data υποδηλώνουν ότι κάποια δεδομένα εισόδου έχουν ήδη επισημανθεί με τη σωστή έξοδο. Κάθε δηλαδή σημείο δεδομένων εισόδου σχετίζεται με την αντίστοιχη ετικέτα (label) εξόδου.
Η επιβλεπόμενη μάθηση μπορεί να χρησιμοποιηθεί για πολλές περιπτώσεις όπως για αξιολόγηση κινδύνου, ανίχνευση απάτης, φιλτράρισμα ανεπιθύμητων μηνυμάτων και πολλά ακόμη.
Πώς Λειτουργεί η Επιβλεπόμενη Μάθηση;
Η επιβλεπόμενη μάθηση χρησιμοποιεί ένα σύνολο μεγάλων δεδομένων (Big Data) εκπαίδευσης, το οποίο περιλαμβάνει εισόδους και σωστές εξόδους, οι οποίες επιτρέπουν στο μοντέλο να μαθαίνει με την πάροδο του χρόνου.
Αρχικά, πραγματοποιείται η συλλογή ενός συνόλου δεδομένων που περιέχει παραδείγματα δεδομένων εισόδου και τις αντίστοιχες σωστές ετικέτες εξόδου. Έπειτα, πραγματοποιείται η εξαγωγή χαρακτηριστικών (feature extraction).
Κάθε σημείο δεδομένων στο σύνολο αυτό αντιπροσωπεύεται από ένα σύνολο χαρακτηριστικών δεδομένων που θα χρησιμοποιήσει το μοντέλο για την πραγματοποίηση προβλέψεων. Στη συνέχεια, αφού οριστούν ορισμένες παράμετροι, το μοντέλο τροφοδοτείται με τα δεδομένα εκπαίδευσης και τις αντίστοιχες ετικέτες τους.
Το μοντέλο μαθαίνει από τα δεδομένα και αφότου εκπαιδευτεί κατάλληλα, αξιολογείται χρησιμοποιώντας ένα σύνολο δεδομένων δοκιμής. Μόλις το μοντέλο εκπαιδευτεί και αξιολογηθεί, μπορεί να χρησιμοποιηθεί για να κάνει προβλέψεις σε νέα δεδομένα, παρέχοντας τις ετικέτες εξόδου με βάση τα χαρακτηριστικά εισόδου.
Αλγόριθμοι Επιβλεπόμενης Μάθησης
Υπάρχουν δύο τύποι αλγορίθμων επιβλεπόμενης μάθησης, η ταξινόμηση (classification) και η παλινδρόμηση (regression)..
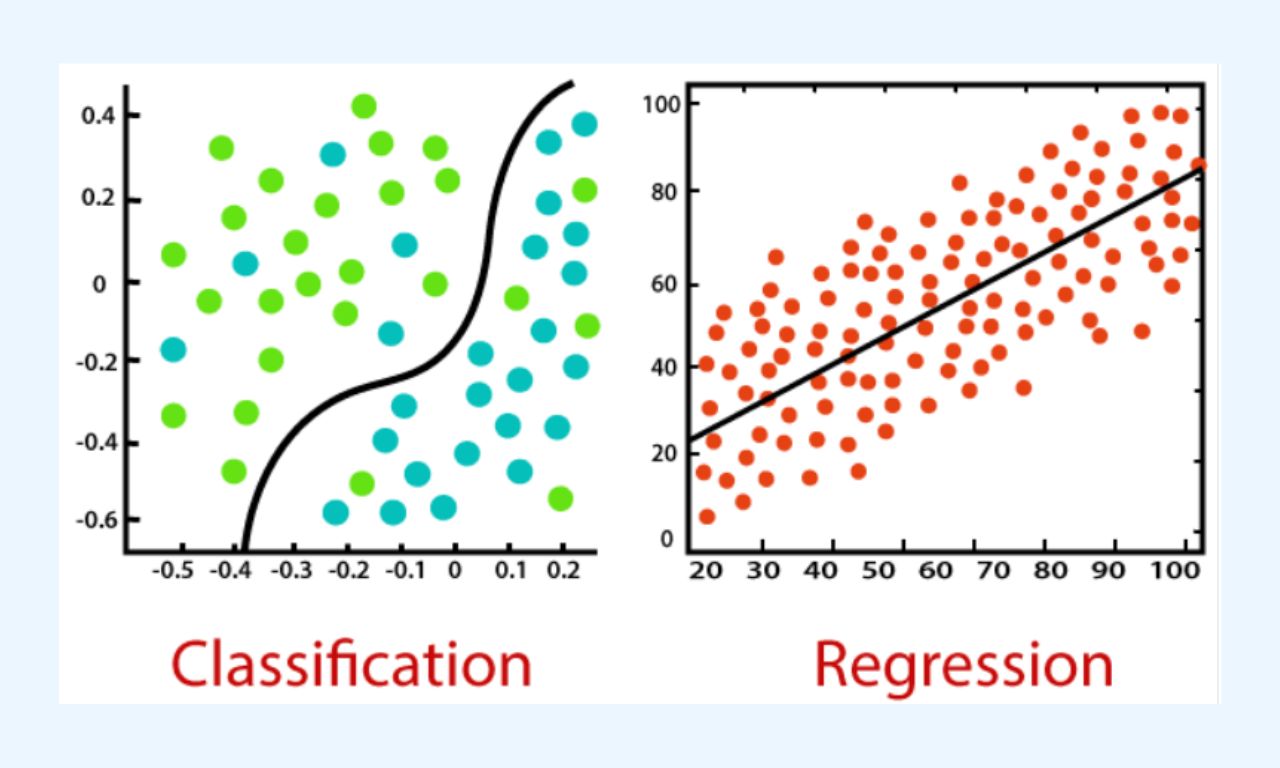
Η ταξινόμηση είναι ένας τύπος επιβλεπόμενης μάθησης όπου οι αλγόριθμοι μαθαίνουν από τα δεδομένα προκειμένου να προβλέψουν ένα αποτέλεσμα ή κάποιο μελλοντικό συμβάν.
Για παράδειγμα, μια τράπεζα με βάση ένα σύνολο δεδομένων πελατών που περιέχει το πιστωτικό ιστορικό τους, μπορεί να προβλέψει αν ο πελάτης θα χρεοκοπήσει με βάση την παρελθοντική του δραστηριότητα, τα δάνεια που πήρε κλπ.
Υπάρχουν πολλοί αλγόριθμοι μηχανικής μάθησης που μπορούν να χρησιμοποιηθούν για εργασίες ταξινόμησης, όπως:
Ο ταξινομητής δέντρου αποφάσεων
Τυχαίος ταξινομητής δασών (Random Forest Classifier)
Τα νευρωνικά δίκτυα (Neural Networks)
Συνεχίζοντας, η παλινδρόμηση είναι ένας τύπος επιβλεπόμενης μάθησης όπου οι αλγόριθμοι μαθαίνουν από τα δεδομένα προκειμένου να προβλέψουν συνεχείς τιμές όπως προβλέψεις εσόδων από πωλήσεις για μια ορισμένη επιχείρηση.
Υπάρχουν πολλοί αλγόριθμοι μηχανικής μάθησης που μπορούν να χρησιμοποιηθούν για εργασίες παλινδρόμησης, όπως:
Η γραμμική παλινδρόμηση
Η παλινδρόμηση δέντρου αποφάσεων
Τα νευρωνικά δίκτυα
Πώς Διαφέρει η Επιβλεπόμενη από την Μη-Επιβλεπόμενη Μάθηση
Στην επιβλεπόμενη μάθηση, τα δεδομένα με ετικέτα είναι δεδομένα που περιέχουν τόσο τα features (μεταβλητές X) όσο και τον στόχο (μεταβλητή Y).
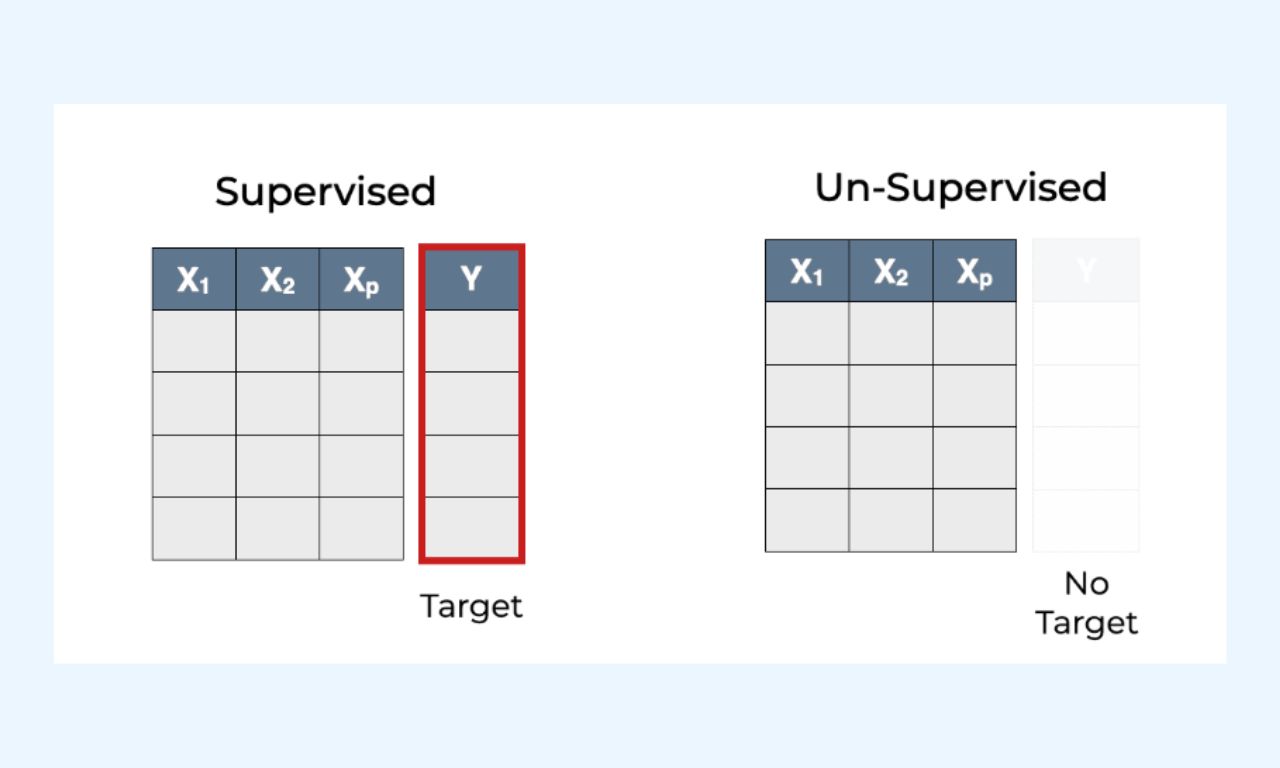
Σε αντίθεση με την επιβλεπόμενη μάθηση, η μη επιβλεπόμενη μάθηση (unsupervised learning) χρησιμοποιεί δεδομένα χωρίς ετικέτα (label).
Από αυτά τα δεδομένα, ανακαλύπτει μοτίβα που βοηθούν στην επίλυση ζητημάτων clustering (συσταδοποίησης) και συσχέτισης (association).
Αυτό είναι ιδιαίτερα χρήσιμο όταν για παράδειγμα οι data scientists μπορεί να μην είναι σίγουροι για κοινές ιδιότητες μέσα σε ένα σύνολο δεδομένων.
Κάποιοι βασικοί αλγόριθμοι συσταδοποίησης είναι οι Hierarchical και K-Means.
Όπως είναι λογικό, τα επιβλεπόμενα μοντέλα μάθησης παράγουν συνήθως πιο ακριβή αποτελέσματα από τη μη επιβλεπόμενη μάθηση, όμως απαιτούν την συμμετοχή του ανθρώπινου παράγοντα αρχικά προκειμένου να προσδιοριστούν σωστά τα δεδομένα.
Από την άλλη πλευρά, τα μοντέλα μάθησης χωρίς επίβλεψη, λειτουργούν αυτόνομα, με βασικό στόχο ενός αλγορίθμου μάθησης χωρίς επίβλεψη, η άντληση πληροφοριών από τεράστιες ποσότητες δεδομένων χωρίς ετικέτες.

Ακολούθως, ας δούμε ορισμένα βασικά παραδείγματα επιβλεπόμενης μάθησης.
3 Παραδείγματα Επιβλεπόμενης Μάθησης
Παράδειγμα #1: Αναγνώριση Εικόνων
Οι αλγόριθμοι επιβλεπόμενης μάθησης μπορούν να χρησιμοποιηθούν για τον εντοπισμό, την απομόνωση και την κατηγοριοποίηση στοιχείων από εικόνες αλλά και βίντεο.
Είναι επομένως ιδιαίτερα χρήσιμοι όταν εφαρμόζονται σε τεχνικές υπολογιστικής όρασης (computer vision) και ανάλυσης εικόνων.
Παράδειγμα #2: Ανάλυση Συναισθήματος
Ένα ακόμα παράδειγμα χρήσης των αλγορίθμων επιβλεπόμενης μάθησης, είναι η ανάλυση συναισθήματος πελατών (sentiment analysis).
Οι οργανισμοί και οι επιχειρήσεις χρησιμοποιώντας αλγόριθμους επιβλεπόμενης μάθησης, μπορούν να κάνουν εξόρυξη δεδομένων και να ταξινομήσουν σημαντικές πληροφορίες από μεγάλους όγκους δεδομένων.
.jpg)
Αυτό είναι ιδιαίτερα χρήσιμο για εταιρείες μάρκετινγκ και εμπορίου για την κατανόηση του συναισθήματος, της πρόθεσης και της γενικότερης αλληλεπίδρασης με τους πελάτες, προκειμένου να βελτιώσουν και να ενισχύσουν την αφοσίωση των πελατών αλλά και τη γενικότερη φήμη της εταιρείας.
Παράδειγμα #3: Ανίχνευση Ανεπιθύμητων Μηνυμάτων (Spam)
Ένα ακόμα σημαντικό παράδειγμα εποπτευόμενου μοντέλου μηχανικής μάθησης είναι η ανίχνευση ανεπιθύμητης αλληλογραφίας.
Κάνοντας χρήση εποπτευόμενων αλγορίθμων ταξινόμησης, οι επιχειρήσεις μπορούν να εκπαιδεύσουν τις βάσεις δεδομένων ώστε να αναγνωρίζουν μοτίβα (patterns) σε νέα δεδομένα, για να προσδιορίζουν αποτελεσματικά εάν τα εισερχόμενα μηνύματα ηλεκτρονικού ταχυδρομείου είναι ανεπιθύμητα ή όχι.
Με Λίγα Λόγια
Είδαμε λοιπόν τι είναι η επιβλεπόμενη μάθηση και πώς λειτουργεί, πώς διαφέρει από την μη-επιβλεπόμενη μάθηση, καθώς και ορισμένα παραδείγματα. Ο χώρος της επιστήμης των δεδομένων προσφέρει πολλές ευκαιρίες επαγγελματικής αποκατάστασης και θέσεων εργασίας με πολύ καλό μισθό.
.jpg)