

Data Pipelines: Definition, Importance & Types
Modern companies, in order to draw conclusions and make informed business decisions based on data, need to follow certain fundamental steps for the collection, organization, and movement of the available data.
This is where data pipelines play a significant role in preparing the data for analysis.
In the field of data science, particularly in data engineering, data pipelines are a fundamental part of the work of data engineers.
In today's article, we will explore:
- What data pipelines are and why they matter
- The different types of data pipelines
- How data pipelines differ from ETL pipelines
What Are Data Pipelines and Why Are They Important?
Data pipelines are a series of steps followed for the collection, organization, and movement of data, ensuring that corporate data is prepared for analysis through proper processing.
Businesses have a large volume of data from various sources such as applications, social media, and Internet of Things (IoT) devices.

Initially, this data is raw, so after extraction from various sources, it needs to be moved to a data storage space, such as a data lake or data warehouse, for analysis.
Before loading data into a data warehouse, it needs to undergo transformation, such as filtering or masking.
The type of data processing required by a data pipeline is usually determined through a combination of exploratory data analysis (EDA) and specific business needs.
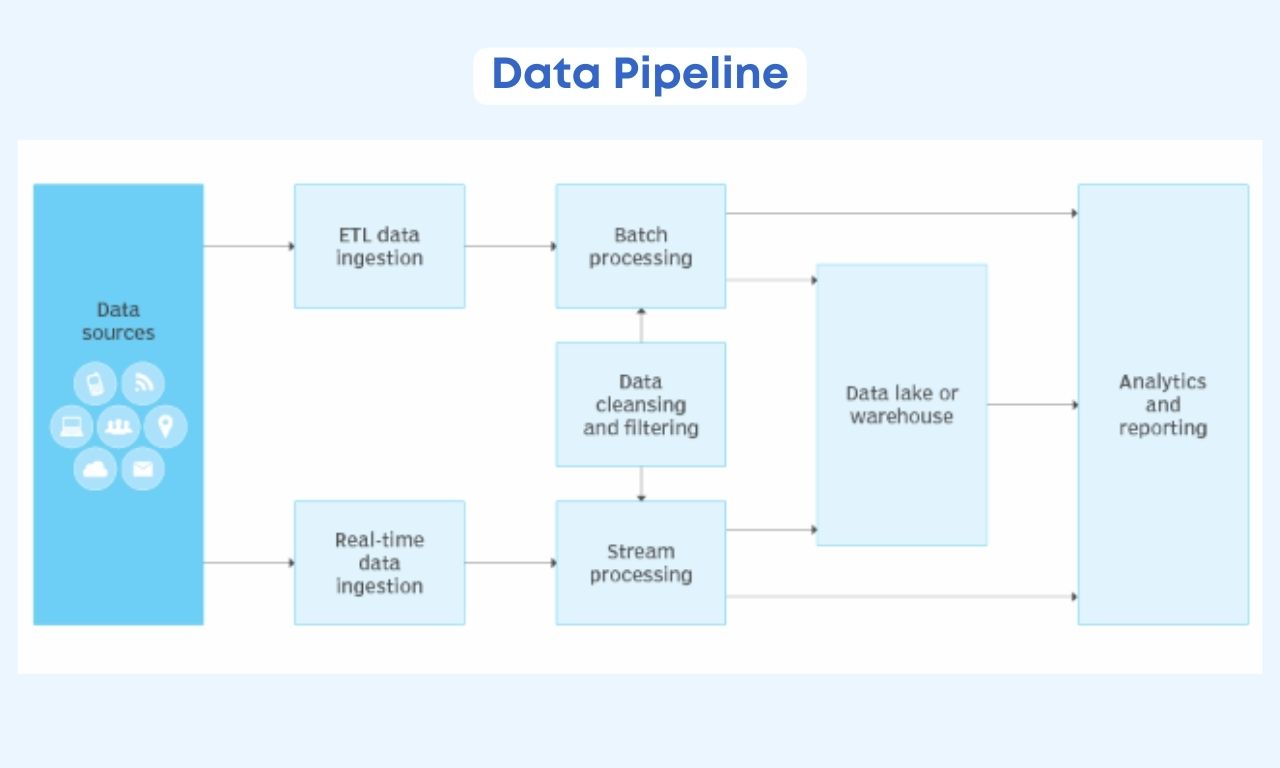
Modern data pipelines contribute significantly to data integration and automate many manual steps involved in the transformation of continuous data loads, facilitating the work of data scientists and data engineers.
Many data pipelines also implement machine learning algorithms and neural networks for more advanced data transformations.
Now that we've covered some basics about data pipelines, let's proceed to the two main types.
The 2 Main Types of Data Pipelines
There are 2 main types of data pipelines, stream processing pipelines and batch processing pipelines.
Type #1: Stream Processing Pipelines
Streaming data pipelines are used when a business process requires a continuous flow of real-time data and continuous updates.
In this case, data is constantly moved from the source to the target, requiring low latency and high fault tolerance.
Additionally, streaming pipelines often involve lower costs and maintenance compared to batch processing pipelines.
Type #2: Batch Processing Pipelines
Batch processing pipelines process and store data in batches.
In this case, data pipelines provide an output of a sequence of commands as input for the next command.
Data is scheduled to load into a storage, such as a cloud data warehouse, during non-peak hours to avoid system overload.
Now, let's see how an ETL pipeline differs from a data pipeline.
How Does an ETL Pipeline Differ from a Data Pipeline?
In the early stages of a data engineer's journey into the world of pipelines, it's understandable not to fully grasp the differences between an ETL pipeline and a data pipeline and use them interchangeably.
Below, we analyze how they differ for better understanding.
An ETL (Extract, Transform, Load) pipeline is a specific type of data pipeline.
ETL tools extract raw data, transform it, and then load it into data lakes or data warehouses.
However, not all data pipelines necessarily follow the ETL process; some may follow the ELT (Extract, Load, Transform) method, where data is extracted from various sources in its raw form, loaded into data lakes, and then transformed.
Ramping Up
We've extensively covered what data pipelines are, their significance, and the primary types that distinguish them.
Thanks to data pipelines, data from diverse sources can be effectively unified, many data transformation processes are automated, and overall, they contribute to the work of data engineers by reducing the processing time of raw data.
If you are intrigued and want to learn more about data pipelines and the world of data science, follow us for more educational articles!
.jpg)