

Data Wrangling: Definition, Steps & Benefits (2024)
In recent years, an increasing number of businesses rely on professionals with data analysis skills to better understand and fully leverage the data at their disposal.
A primary concern of a data analyst is, of course, processing and cleaning this data to make it usable for a company.
In our previous articles, we discussed various data processes such as data cleaning and data mapping.
In today's article, we will take a look at some fundamental aspects of data wrangling.
More specifically we will answer the following questions:
- What is data wrangling?
- What advantages does it offer?
- What steps and processes are involved?
Let's start with the basics.
What is Data Wrangling?
Data wrangling is a series of processes and steps followed to transform raw data into a format suitable for analysis.
The procedures in data wrangling, such as reorganizing, cleaning, and transforming data from a 'raw' form to another, are crucial in the field of data science, as raw data is often messy and incomplete.
Thanks to data wrangling, businesses can handle more complex data in less time and with greater accuracy.
Now, let's delve into the key advantages offered by data wrangling.
What Advantages Does Data Wrangling Offer?
Businesses often face a rapid expansion of data volume and available sources.
This fact makes storing and organizing large amounts of data for analysis increasingly necessary.
The advantages provided by data wrangling include:
Advantage #1: Improved data quality
Data wrangling helps identify and address issues such as missing values, outliers, inconsistencies, and errors in data.
This results in data characterized by greater accuracy and better quality.
Advantage #2: Better compatibility
Through data wrangling, data from different sources, such as files, APIs, and databases, can be integrated and analyzed together, making it compatible for use in various analytical tools by data teams.
Advantage #3: Cost and time efficiency
By automating repetitive tasks and identifying gaps and outliers in data, data wrangling contributes to data security and can save valuable time and money.
Having explored some basic aspects of data wrangling and its advantages, let's move on to the steps involved.
What Steps does Data Wrangling Involve?
The steps in data wrangling are as follows:
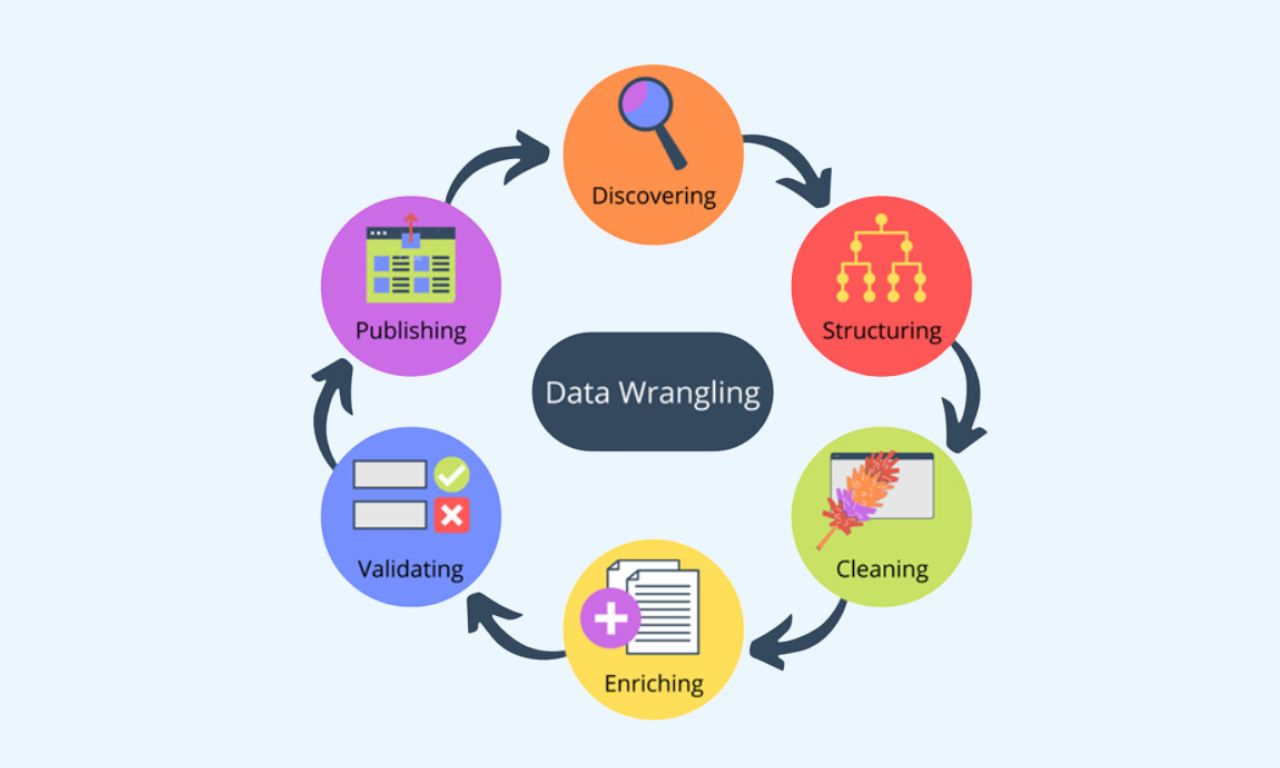
Step #1: Data exploring
Initially, as the first step, an exploration of the data is necessary, identifying trends and patterns, along with issues such as missing or extreme values that need addressing.
Step #2: Data transformation
Raw data usually cannot be used in its unprocessed form.
Transformation is needed to convert it into a structure compatible with the analytical model one wishes to use for data analysis.
This involves normalization and denormalization processes, followed by data cleaning to eliminate errors that may negatively impact accuracy.
After the data has been successfully transformed by data analysts into a more usable format, they can, if necessary, enrich the data by adding values from other data sets.
Step #3: Data validation
In the data validation step, what came before in the previous stage of the transformation is checked and verified.
Step #4: Data publishing
In the final step, after diligently following all the above processes, data can be published and shared with other members of the data team.
Ramping Up
We have explored what data wrangling is, the advantages it offers, and the steps and processes involved.
Data wrangling is an integral part of a data analyst's work, ensuring consistency, accuracy, and improved data quality for the analysis of crucial business decisions.
If you are intrigued and want to learn more about the world of big data analytics and data science in general, follow us for more educational articles!
.jpg)