
.png)
Μια Μέρα στη Ζωή ενός AI Engineer
Φανταστείτε αυτό: είναι 9 π.μ., το Slack σας χτυπάει ήδη ασταμάτητα και δεν έχετε αγγίξει ακόμα ούτε μια γραμμή κώδικα. Καλώς ορίσατε στον κόσμο ενός AI engineering.
Ο τίτλος της θέσης εργασίας ακούγεται σαν κάτι από ταινία επιστημονικής φαντασίας, αλλά η πραγματικότητα είναι ταυτόχρονα πιο προσγειωμένη και πολύ πιο ενδιαφέρουσα από τη δημοφιλή εικόνα. Οι AI engineers δεν είναι ερευνητές που επινοούν θεωρητικές φόρμουλες σε ένα εργαστήριο. Είναι οι δημιουργοί που παίρνουν αυτά τα μοντέλα και γεφυρώνουν το χάσμα μεταξύ του «αυτό το demo φαίνεται καλό» και του «αυτό τρέχει αξιόπιστα στις 2:00 π.μ. για δέκα χιλιάδες χρήστες».
Πώς μοιάζει, λοιπόν, μια τυπική μέρα;
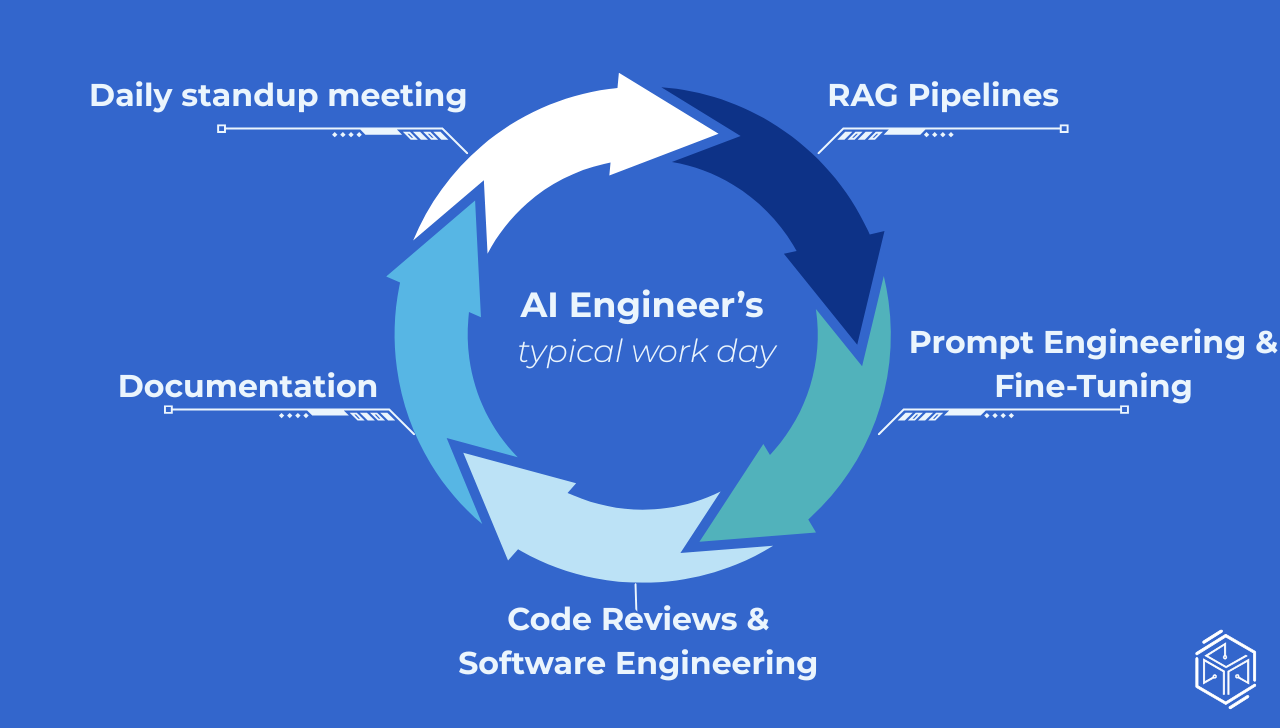
09:00 — Το Πρωινό Δεν Ξεκινά με Κώδικα
Το πρώτο πράγμα που κάνουν οι περισσότεροι AI engineers το πρωί δεν είναι να γράψουν κώδικα. Όπως σε κάθε άλλη δουλειά, το πρωί είναι κρατημένο για το daily standup: μια σύντομη ομαδική συνάντηση (sync) 15 λεπτών, όπου όλοι αναφέρουν τι ολοκλήρωσαν χθες, με τι ασχολούνται σήμερα και αν έχουν εκκρεμότητες που τους μπλοκάρουν.
Ακούγεται ως κάτι τυπικό, αλλά στις ομάδες AI φέρνει γρήγορα στην επιφάνεια πραγματικά ζητήματα συντονισμού: μια αλλαγή σε ένα prompt που επηρεάζει τη διαδικασία αξιολόγησης (evaluation pipeline) ενός άλλου μηχανικού, μια ενημέρωση μοντέλου που πρέπει να ελεγχθεί πριν από το sprint review της εβδομάδας, ή μια ανωμαλία στην παραγωγή (production) που δεν είχε παρατηρήσει κανείς ακόμα.
Μετά το standup, και πριν ξεκινήσει η συγκεντρωμένη εργασία, οι περισσότεροι μηχανικοί κάνουν έναν γρήγορο έλεγχο παρακολούθησης (monitoring review) σε εργαλεία όπως το Datadog ή το Grafana. Τα συστήματα AI παραγωγής τρέχουν 24/7 και αποτυγχάνουν με τρόπους που είναι εκπληκτικά ανεπαίσθητοι. Σπάνια πρόκειται για ένα απότομο κρασάρισμα (crash). Τις περισσότερες φορές είναι μια αργή, αθόρυβη υποβάθμιση:
Απότομες αυξήσεις στο κόστος των Tokens: Κάθε κλήση στο API ενός γλωσσικού μοντέλου κοστίζει χρήματα ανά token που επεξεργάζεται. Μια έξαρση στη χρήση στις 3 π.μ. χωρίς προφανή αιτία είναι ταυτόχρονα ένα bug και ένας απροσδόκητος λογαριασμός.
- Δείκτες ποιότητας απόκρισης (Response quality signals): Έμμεσοι μετρικοί δείκτες (proxy metrics) όπως το feedback των χρηστών, τα ποσοστά απόρριψης, τα ποσοστά επαναδοκιμής (retry rates) και οι κατανομές των σκορ εμπιστοσύνης βοηθούν στον εντοπισμό της πτώσης στην ποιότητα των απαντήσεων που παράγει το AI, ακόμη και αν το σύστημα φαίνεται να λειτουργεί κανονικά.
- Prompt Drift (Ολίσθηση Prompt): Τα αιτήματα και η συμπεριφορά των χρηστών αλλάζουν με την πάροδο του χρόνου. Καθώς εμφανίζονται νέοι τύποι ερωτήσεων, τα prompts και τα workflows που προηγουμένως απέδιδαν καλά, μπορεί να γίνουν λιγότερο αποτελεσματικά.
- Ποιότητα Ανάκτησης (Retrieval quality): Στα συστήματα RAG (Retrieval-Augmented Generation), η ποιότητα των πληροφοριών που ανακτώνται επηρεάζει άμεσα την ακρίβεια των απαντήσεων. Τα παρωχημένα έγγραφα, τα κακά embeddings ή τα λάθος ρυθμισμένα indexes παρέχουν λανθασμένο πλαίσιο (context), οδηγώντας το μοντέλο στο να παράγει ανακριβείς απαντήσεις με μεγάλη... αυτοπεποίθηση.
Σε μια ήσυχη μέρα, αυτό το monitoring παίρνει τριάντα λεπτά. Σε μια όχι και τόσο ήσυχη, απορροφά όλο το πρωινό.
10:30 — Deep Work: Χτίζοντας το Retrieval Pipeline
Αν υπάρχει ένας τομέας που καθορίζει ένα μεγάλο μέρος της πρακτικής εργασίας ενός AI engineer αυτή τη στιγμή, αυτός είναι το RAG (Retrieval-Augmented Generation).
Το πρόβλημα που λύνει είναι θεμελιώδες: τα γλωσσικά μοντέλα γνωρίζουν μόνο όσα περιλαμβάνονταν στα δεδομένα εκπαίδευσής τους. Τη στιγμή που ένα προϊόν πρέπει να απαντήσει σε ερωτήσεις σχετικά με εσωτερικά έγγραφα, πρόσφατα δεδομένα ή οτιδήποτε ιδιωτικό/εταιρικό, ένα βασικό μοντέλο δεν αρκεί. Η σχετική πληροφορία πρέπει να ανακτηθεί κατά τον χρόνο εκτέλεσης (runtime) και να τροφοδοτηθεί στο μοντέλο μαζί με το ερώτημα του χρήστη.
Το χτίσιμο αυτού του pipeline είναι το σημείο όπου γίνεται η βαθιά, συγκεντρωμένη δουλειά:
- Ingestion (Εισαγωγή Δεδομένων): Τα πρωτογενή έγγραφα (PDFs, wikis, εξαγωγές από βάσεις δεδομένων) εξάγονται, καθαρίζονται και χωρίζονται σε κομμάτια (chunks). Το μέγεθος μετράει: αν είναι πολύ μικρά, το μοντέλο χάνει το context· αν είναι πολύ μεγάλα, η ακρίβεια πέφτει.
- Embedding και Αποθήκευση: Κάθε κομμάτι μετατρέπεται σε διάνυσμα (vector) και αποθηκεύεται σε μια βάση δεδομένων όπως το Pinecone, το Qdrant ή το pgvector, επιτρέποντας γρήγορη σημασιολογική αναζήτηση (semantic search) ανάμεσα σε εκατομμύρια έγγραφα.
- Λογική Ανάκτησης (Retrieval Logic): Η απλή αναζήτηση ομοιότητας είναι μόνο η αρχή. Τα πιο έξυπνα συστήματα συνδυάζουν τη διανυσματική αναζήτηση με αντιστοίχιση λέξεων-κλειδιών (keyword matching) και επίπεδα επανακατάταξης (re-ranking layers) για να βελτιώσουν αυτό που φτάνει τελικά στο μοντέλο.
- Generation Prompt: Το περιεχόμενο που ανακτήθηκε, η ερώτηση του χρήστη και οι οδηγίες ενώνονται σε ένα τελικό prompt, σχεδιασμένο να παράγει ακριβείς απαντήσεις — και να λέει ξεκάθαρα «δεν γνωρίζω» όταν η πληροφορία δεν υπάρχει.
-
13:00 — Prompt Engineering & Fine-Tuning
Στα συστήματα παραγωγής, τα prompts αντιμετωπίζονται ως πηγαίος κώδικας (source code) και όχι ως απλές, πρόχειρες οδηγίες. Αποθηκεύονται σε συστήματα ελέγχου εκδόσεων (Git), αξιολογούνται από συναδέλφους (peer review) και επικυρώνονται έναντι συνόλων δεδομένων αξιολόγησης (evaluation datasets) πριν από το deployment. Οποιαδήποτε αλλαγή πρέπει να βελτιώνει τη συνολική απόδοση — αν διορθώνει κάποια προβλήματα αλλά εισάγει νέα, δεν κυκλοφορεί.
Όταν το απλό prompt engineering φτάνει στα όριά του, το απόγευμα μετατοπίζεται στο Fine-Tuning: τη λήψη ενός έτοιμου μοντέλου (foundation model) και τη συνέχιση της εκπαίδευσής του σε ένα εξειδικευμένο σύνολο δεδομένων χρησιμοποιώντας PyTorch ή Hugging Face. Καθώς τρέχει η εκπαίδευση, οι μηχανικοί παρακολουθούν τις καμπύλες απώλειας (loss curves) στο Weights & Biases για να εντοπίσουν έγκαιρα το overfitting (υπερεκπαίδευση), και στη συνέχεια συγκρίνουν (benchmark) το νέο μοντέλο με τα πρότυπα παραγωγής πριν λάβουν οποιαδήποτε απόφαση αναβάθμισης.
Παράλληλα, οι μηχανικοί χτίζουν και συντονίζουν όλο και περισσότερο αυτόνομους πράκτορες (autonomous agents): συστήματα που δεν απαντούν απλώς σε ερωτήματα, αλλά σχεδιάζουν και εκτελούν ανεξάρτητα εργασίες πολλαπλών βημάτων. Είναι ένας από τους πιο γρήγορα αναπτυσσόμενους τομείς στον κλάδο και γίνεται βασικό κομμάτι των εργαλείων AI σε περιβάλλον παραγωγής.
15:00 - Code Reviews & Καθαρό Software Engineering
Εδώ είναι το κομμάτι που σπάνια εμφανίζεται στις φανταχτερές αγγελίες εργασίας: ένα μεγάλο μέρος της ημέρας είναι απλό, κλασικό software engineering. Pull requests, code review, εργασίες ενοποίησης συστημάτων (integration) και ticket triage.
Η διαφορά βρίσκεται στην οπτική γωνία. Ένα code review ειδικά για AI σημαίνει να θέτεις ερωτήματα που ένας γενικός μηχανικός λογισμικού μπορεί να παραλείψει:
Υπάρχει διαχείριση χρονικού ορίου (timeout handling) σε αυτή την κλήση API του LLM; Τι συμβαίνει αν το μοντέλο κάνει 45 δευτερόλεπτα να απαντήσει — «παγώνει» η εφαρμογή;
Τι συμβαίνει όταν το μοντέλο επιστρέφει κακοσχηματισμένο JSON; Ο parser μας αποτυγχάνει με ασφάλεια (fail safely) ή κρασάρει ολόκληρο το σύστημα;
Μήπως ευαίσθητα δεδομένα χρηστών περνούν κατά λάθος μέσα από ένα τρίτο API που δεν θα έπρεπε να αγγίξουν;
16:30 - Documentation (Η συνήθεια που σώζει τους πάντες στις 11 το βράδυ)
Όπως ξέρουμε, αυτό δεν είναι το αγαπημένο κομμάτι κανενός, αλλά είναι μία από τις συνήθειες με την υψηλότερη αξία (high-leverage) στη δουλειά.
Γιατί έχει σημασία το documentation; Η συμπεριφορά ενός συστήματος AI εξαρτάται από την έκδοση του μοντέλου, τη διαμόρφωση του prompt, τη φρεσκάδα των δεδομένων και τις ρυθμίσεις της υποδομής — όλα ταυτόχρονα. Όταν κάτι σπάσει μετά από έξι μήνες και το άτομο που είναι σε εφημερία (on call) δεν είναι αυτό που το έχτισε, το καλό documentation είναι η διαφορά ανάμεσα σε μια διόρθωση 20 λεπτών και σε ένα live incident 4 ωρών. Το ιστορικό εκδόσεων των prompts, οι αποφάσεις αρχιτεκτονικής, τα runbooks για επαναλαμβανόμενα περιστατικά — οι καλύτεροι μηχανικοί τα αντιμετωπίζουν όλα αυτά ως μέρος της δουλειάς, όχι ως επιπλέον γραφειοκρατικό φόρτο.
Το Tech Stack του AI Engineer
Μιλώντας για hard skills, υπάρχει ένα βασικό tech stack που χρησιμοποιείται καθημερινά στα modern AI engineering workflows:
Γλώσσες & Frameworks: Python, FastAPI, PyTorch.
Orchestration & Δεδομένα: LangChain, LlamaIndex, Pandas, SQL/NoSQL.
Διανυσματικές Υποδομές (Vector Infrastructure): Pinecone, Qdrant, pgvector.
Deployment & MLOps: Docker, AWS ή Azure, Git, Weights & Biases.
Επιπλέον, υπάρχει ένα πράγμα που κανένα εργαλείο δεν αντικαθιστά: την ανθρώπινη κρίση. Το να γνωρίζεις ποιο metric να εμπιστευτείς, πότε ένα μοντέλο είναι αρκετά καλό για να γίνει deploy, και τότε κάτι δεν πάει καλά, ακόμη και αν τα νούμερα φαίνονται τέλεια — αυτή είναι η δεξιότητα που ξεχωρίζει έναν απλώς καλό AI engineer από έναν κορυφαίο. Τα εργαλεία διαχειρίζονται την κλίμακα. Ο μηχανικός διαχειρίζεται τις αποφάσεις.
Είναι Αυτή η Κατάλληλη Καριέρα για Εσάς;
Το AI engineering βρίσκεται στο απόλυτο σημείο τομής του software engineering, της επιστήμης δεδομένων (data science) και της προϊοντικής σκέψης (product thinking), χωρίς να ανήκει ολοκληρωτικά σε κανένα από αυτά. Για τον κατάλληλο άνθρωπο, αυτή ακριβώς είναι η γοητεία του.
Αν σας ελκύει μια δουλειά όπου τα εργαλεία εξελίσσονται συνεχώς, τα προβλήματα είναι πραγματικά νέα και η μηχανική σας κρίση αποτυπώνεται απευθείας σε αυτό που κυκλοφορεί στην αγορά — είναι ένα συναρπαστικό μέρος για να χτίσετε καριέρα. Η παγκόσμια ζήτηση για άτομα που μπορούν να κάνουν ουσιαστικά αυτή τη δουλειά αυξάνεται εκθετικά.
Στην Big Blue Academy, το εντατικό μας AI Engineering Bootcamp είναι χτισμένο εξολοκλήρου γύρω από αυτούς τους πρακτικούς, πραγματικούς πυλώνες: Python, προηγμένες αρχιτεκτονικές RAG, PyTorch και έτοιμους για παραγωγή αυτόνομους πράκτορες (autonomous agents).
Είστε έτοιμοι να κυριαρχήσουν στον end-to-end lifecycle του AI;
.jpg)