
.png)
A Day in the Life of an AI Engineer
Imagine this: it's 9am, your Slack is already pinging, and you haven't touched a line of code yet. Welcome to AI engineering.
The job title sounds like something from a sci-fi film, but the reality is both more grounded and more interesting than the popular image. AI engineers aren't researchers dreaming up theoretical formulas in a lab. They are the builders who take those models and bridge the gap between "this demo looks good " and "this runs reliably at 2:00 AM for ten thousand users."
So, what does a typical day actually look like?
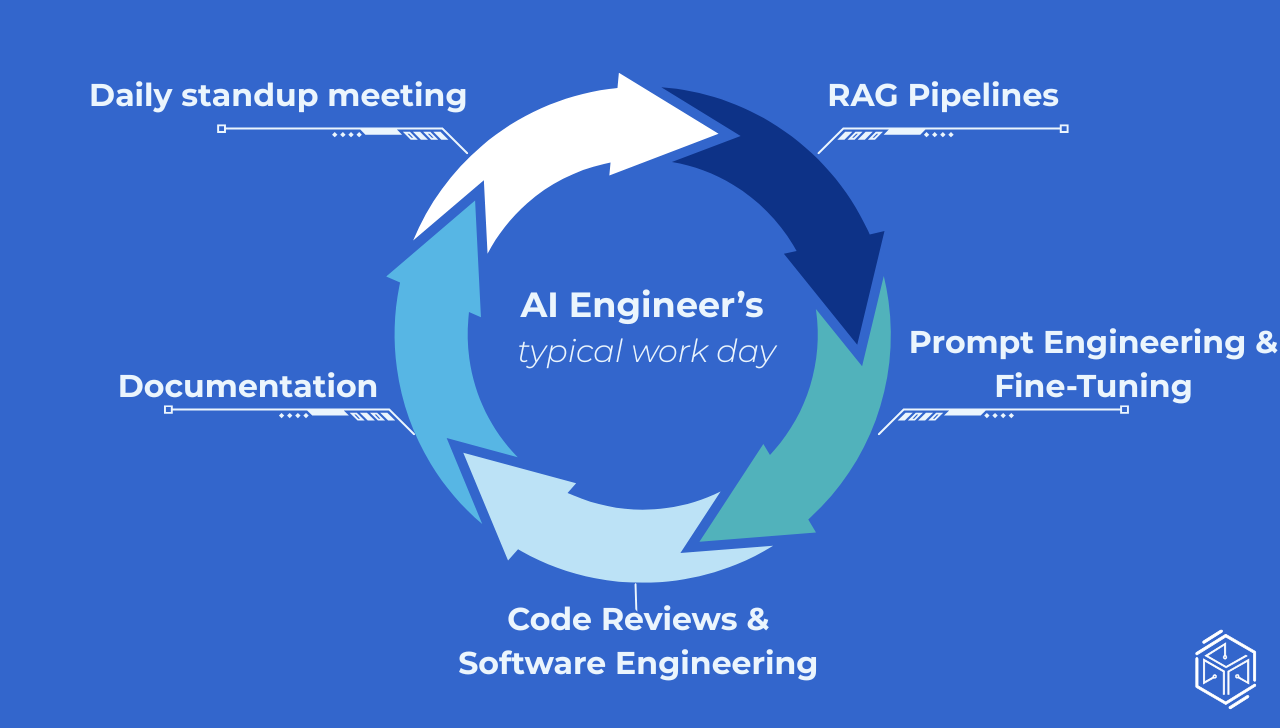
09:00: The Morning Doesn't Start With Code
The first thing most AI engineers do in the morning isn't write code. Like any other job, morning is reserved for daily standup: a short team sync, usually 15 minutes, where everyone covers what they shipped yesterday, what they're working on today, and whether they have any pending tasks. It sounds as routine, but in AI teams it often surfaces real coordination issues fast: a prompt change that affects another engineer's evaluation pipeline, a model update that needs to be tested before the week's sprint review, a production anomaly nobody noticed yet.
After the standup, before the deep work begins, most engineers run a quick monitoring review in tools like Datadog or Grafana. Production AI systems run 24/7, and they fail in ways that are surprisingly subtle. It's rarely a crash. More often it's a slow, quiet degradation: response quality slipping, costs creeping up, behavior drifting away from what was intended. The checklist looks like this:
- Token cost spikes. Every call to a language model API costs money per token processed. A usage spike at 3am with no obvious cause is both a bug and an unexpected bill.
- Response quality signals. Proxy metrics such as user feedback, rejection rates, retry rates, and confidence score distributions help identify when the quality of AI-generated responses is declining, even if the system appears to be functioning normally.
- Prompt drift. User requests and behavior change over time. As new types of questions emerge, prompts and workflows that previously performed well may become less effective, causing gradual performance degradation if not updated.
- Retrieval quality. In Retrieval-Augmented Generation (RAG) systems, the quality of retrieved information directly affects answer accuracy. Outdated documents, poor embeddings, or misconfigured indexes can provide incorrect context, leading the model to generate inaccurate responses confidently.
In case you are wondering how much time this takes…On a quiet day, this takes thirty minutes. On a not-so-quiet one, it becomes the whole morning.
10:30- Deep Work: Building the Retrieval Pipeline
If there's one area that defines a large portion of practical AI engineering work right now, it's RAG — Retrieval-Augmented Generation.
The problem it solves is fundamental: language models only know what they were trained on. The moment a product needs to answer questions about internal documents, recent data, or anything proprietary, a base model isn't enough. The relevant information needs to be retrieved at runtime and fed in alongside the query.
Building that pipeline is where a lot of the deep, focused work happens:
- Ingestion. Raw documents- PDFs, wikis, database exports- get extracted, cleaned, and split into chunks. Size matters: too small and the model loses context, too large and precision drops.
- Embedding and storage. Each chunk gets converted into a vector and stored in a database like Pinecone, Qdrant, or pgvector, enabling fast semantic search across millions of documents.
- Retrieval logic. Basic similarity search is just the starting point. Smarter setups combine vector search with keyword matching and re-ranking layers to improve what actually reaches the model.
- Generation prompt. The retrieved context, the user's question, and the instructions all come together into a prompt designed to produce accurate answers — and say "I don't know" cleanly when the information isn't there.
When everything comes together smoothly, it is one of the most rewarding parts of the job. When it does not, diagnosing and resolving the issues can become a time-consuming process that lasts for days or even weeks.
13:00 — Prompt Engineering & Fine-Tuning
In production systems, prompts are treated as source code rather than informal instructions. They are stored in version control, reviewed by peers, and validated against evaluation datasets before deployment. Any change must improve overall performance—if it fixes some issues but introduces new ones, it is not released.
When standard prompting hits a ceiling, the afternoon shifts to fine-tuning: taking a foundation model and continuing its training on a custom dataset using PyTorch or Hugging Face. While the run executes, engineers monitor loss curves in Weights & Biases to catch overfitting early, then benchmark the new model against production before making any promotion decision.
Increasingly, engineers are also building and orchestrating autonomous agents: systems that don't just respond to queries, but plan and execute multi-step tasks independently. It's one of the fastest-moving areas in the field, and one that's quickly becoming a core part of the production AI toolkit.
15:00 - Code Reviews & Pure Software Engineering
Here's the part that rarely makes it onto the job posting: a big chunk of the day is just regular software engineering. Pull requests, code review, integration work, ticket triage.
The difference is the point of view. AI-specific review means asking questions a general engineer might miss: is there timeout handling on this LLM API call? What happens when the model returns malformed JSON? Is sensitive user data accidentally passing through a third-party API? These aren't edge cases. They're the things that quietly take down production systems.
16:30 - Documentation (The Habit That Saves Everyone at 11pm)
As we know, this is nobody's favorite part, but one of the highest-leverage habits in the job.
Why does documentation matter?
AI system behavior depends on the model version, prompt config, data freshness, and infrastructure, all at once. When something breaks six months from now and the person on call isn't the person who built it, good documentation is the difference between a twenty-minute fix and a four-hour incident. Prompt version history, architecture decisions, runbooks for recurring incidents - the best engineers treat this as part of the work.
The AI Engineer's Tech Stack
Talking about hard skills, there is a core tech stack commonly used in modern AI engineering workflows:
Languages & frameworks: Python, FastAPI, PyTorch.
Orchestration & data: LangChain, LlamaIndex, Pandas, SQL/NoSQL.
Vector infrastructure: Pinecone, Qdrant, pgvector.
Deployment & MLOps: Docker, AWS or Azure, Git, Weights & Biases.
In addition, there is one thing no tool replaces: human judgment. Knowing which metric to trust, when a model is good enough to ship, and when something feels off even if the numbers look fine- that's the skill that separates a solid AI engineer from a great one.
The tools handle the scale. The engineer handles the decisions.
Is This the Right Career for You?
AI engineering sits at the ultimate intersection of software engineering, data science, and product thinking, without fully belonging to any single one of them. For the right kind of person, that's exactly the appeal.
If you're drawn to work where the tools are evolving, the problems are genuinely new, and your engineering judgment shows up directly in what ships- it's a compelling place to build a career. The global demand for people who can actually do this work is growing.
At Big Blue Academy, our immersive AI Engineering Bootcamp is built entirely around these practical, real-world pillars: Python, advanced RAG architectures, PyTorch, and production-ready autonomous agents.
Ready to master the end-to-end AI lifecycle?
.jpg)