
-2.jpg)
8 Essential Python Libraries for Data Scientists
Python, one of the most popular programming languages, is widely used for various purposes thanks to its simplicity, beginner-friendly nature, and extensive collection of libraries. It finds applications in fields like data science and machine learning.
With comprehensive documentation and a staggering library count of over 137,000, Python has become a staple for programmers.
In this article, we'll delve into some fundamental Python libraries for Data Scientists, specifically focusing on the following:
TensorFlow
PyTorch
Numpy
Pandas
Scikit-Learn
Keras
Matplotlib
LightGBM
Let's begin with the first library.
Library #1: TensorFlow
TensorFlow, developed by Google's Brain team, is an open-source library popular for its versatility and extensive range of tools, libraries, and resources.
It caters to researchers, programmers, and machine learning enthusiasts.

Chances are, if you've worked on a machine learning project using Python, you're familiar with TensorFlow.
- Some key features include:
- Easy model development
- Integration of pre-trained models and datasets
- Compatibility with Keras
Rich API support, including low and high-level APIs in Python and C
Library #2: PyTorch
PyTorch, a machine learning library, significantly accelerates the process from research prototyping to production development. It offers APIs for solving neural network-related application problems.
Designed for efficient deep learning using both GPU and CPU, PyTorch stands as an alternative to TensorFlow.
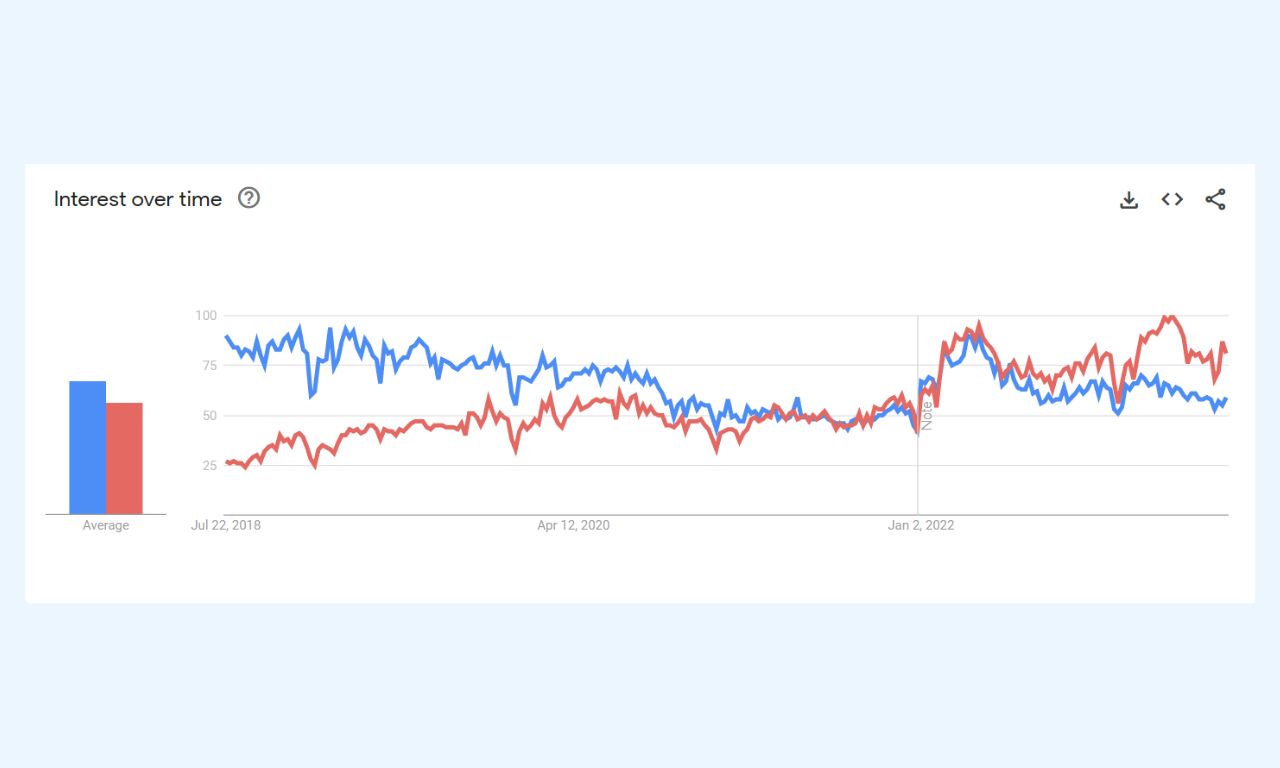
Over time, PyTorch’s popularity (in red color) has even surpassed TensorFlow (in blue color), as evident in Google Trends data.
Library #3: NumPy
NumPy, a widely-used open-source Python library, is pivotal for scientific computations. With its embedded mathematical functions, it supports multi-dimensional data.

Preferred for its efficient memory use, NumPy Arrays are often favored over NumPy Lists.
The library's development is driven by the extensive Python scientific community.
Library #4: Pandas
Pandas, an open-source library, is particularly cherished by data scientists. It is widely used for data analysis, manipulation, and cleaning.
Pandas simplifies modeling and data analysis tasks with minimal code.
Some key features of this library that make it particularly flexible and accessible include the following:
- DataFrames, which allow direct and efficient data manipulation and include built-in indexing
- Merging and joining high-performance datasets
- A wide range of tools that enable users to write and read data between different data structures in memory and various formats (such as Excel files, text files, CSV, SQL databases)
Library #5: Scikit-Learn
The Scikit-learn library is one of the most widely used machine learning libraries in Python.
It was initially launched in 2007 as a Google Summer of Code project, and since then, it has been further developed with the contribution of a large community of scientists.
It is user-friendly and encompasses a multitude of algorithms for implementing standardized machine learning and data mining tasks, such as classification, regression, and clustering.
Library #6: Keras
Continuing, Keras is a machine learning library in Python that offers simple APIs, minimizing the number of user actions required for common use cases.
It also provides utility programs for data set processing and graph visualization, among other things.

Its main distinguishing features include:
- Smooth operation on both CPU and GPU
- Support for nearly all neural network models
- Flexibility, user-friendliness, and error detection
Additionally, TensorFlow adopted Keras as its default API in TF version 2.0.
Library #7: Matplotlib
Matplotlib is a library for creating static, interactive, and animated Python visualizations.
Matplotlib is open-source and empowers users to visualize data using a wide range of chart types, such as histograms, bar graphs, and scatter plots.
Moreover, visualizations can be achieved with just a few lines of code.
Library #8: LightGBM
LightGBM is a popular open-source gradient boosting library that utilizes tree-based algorithms.

Equivalent libraries that offer similar functionalities and solve corresponding problems include XGBoost and CatBoost.
The LightGBM library offers the following advantages:
- Low memory usage
- Significant accuracy
- Ability to handle large-scale data
Furthermore, it can be used for supervised classification tasks as well as regression tasks.
Ramping Up
One of the reasons why Python is so valuable for data science is its vast collection of data handling, data visualization, machine learning, and library tools.
Whether you're building your own project or advancing in your data science career, learning Python can be a game-changer.
If you are excited and want to read more about Python and Data Science, follow us for more educational articles!
.jpg)