

Similarity Learning: Definition, Methods & Applications
Machine Learning continually brings new advancements to various business sectors, thanks to the advantages it offers in strategic decision-making, profit enhancement, and competition management.
Supervised and unsupervised machine learning, extensively discussed in our previous articles, are two fundamental subcategories of machine learning, each serving distinct purposes.
Today, our focus is on similarity learning, a subcategory of supervised learning widely employed in face recognition systems and recommendations.
More specifically in this guide, we'll explore:
- What is similarity learning?
- Basic methods it employs
- Some fundamental use cases
Let's start with the basics.
What is Similarity Learning?
Similarity Learning is a branch of machine learning that concentrates on training machine learning models to recognize similarities or dissimilarities between data points.
Algorithms in similarity learning initially create a representation for each element in a dataset in the form of vectors.
The distance between these vectors indicates how similar or dissimilar the data points are.
The smaller the distance, the greater their similarity.
In contrast to more traditional supervised learning, similarity learning doesn't always require labels but rather a reference point to determine the similarity between the examined elements.
Thanks to similarity learning, machines can better understand various patterns, relationships, and structures in data, enabling effective anomaly detection.
Now that we've covered the basics, let's delve into the different methods it employs.
Methods of Similarity Learning
Some basic methods in the field of similarity learning are the following:
Method #1: Cosine similarity
Cosine similarity measures the similarity between two vectors by calculating the cosine of the angle between them.
If the cosine is 1, there is maximum similarity; if it's 0, there is no commonality between the vectors.
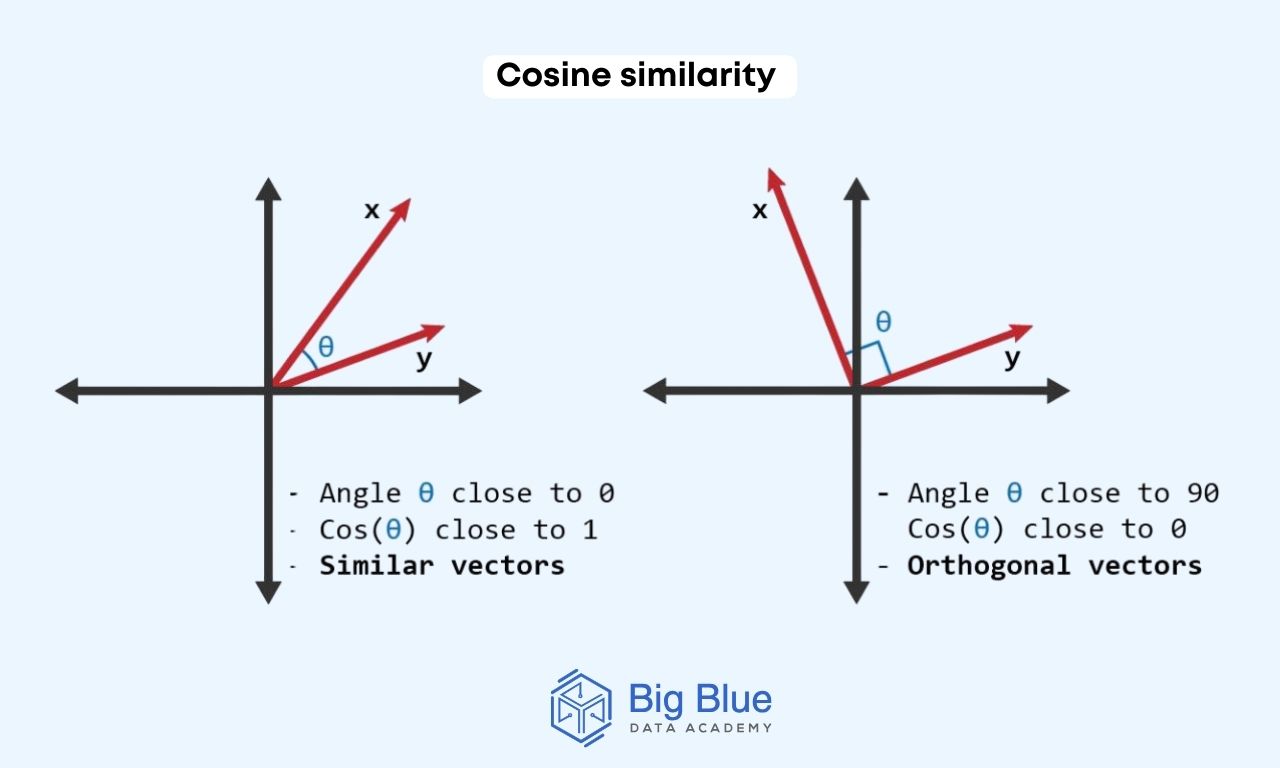
This method is widely used in data science, particularly in Natural Language Processing (NLP), for text analysis and finding similarities.
Method #2: Siamese networks
Siamese networks consist of two identical subnetworks sharing common weights.
They are trained to produce similar representations for similar input pairs and dissimilar representations for dissimilar input pairs.
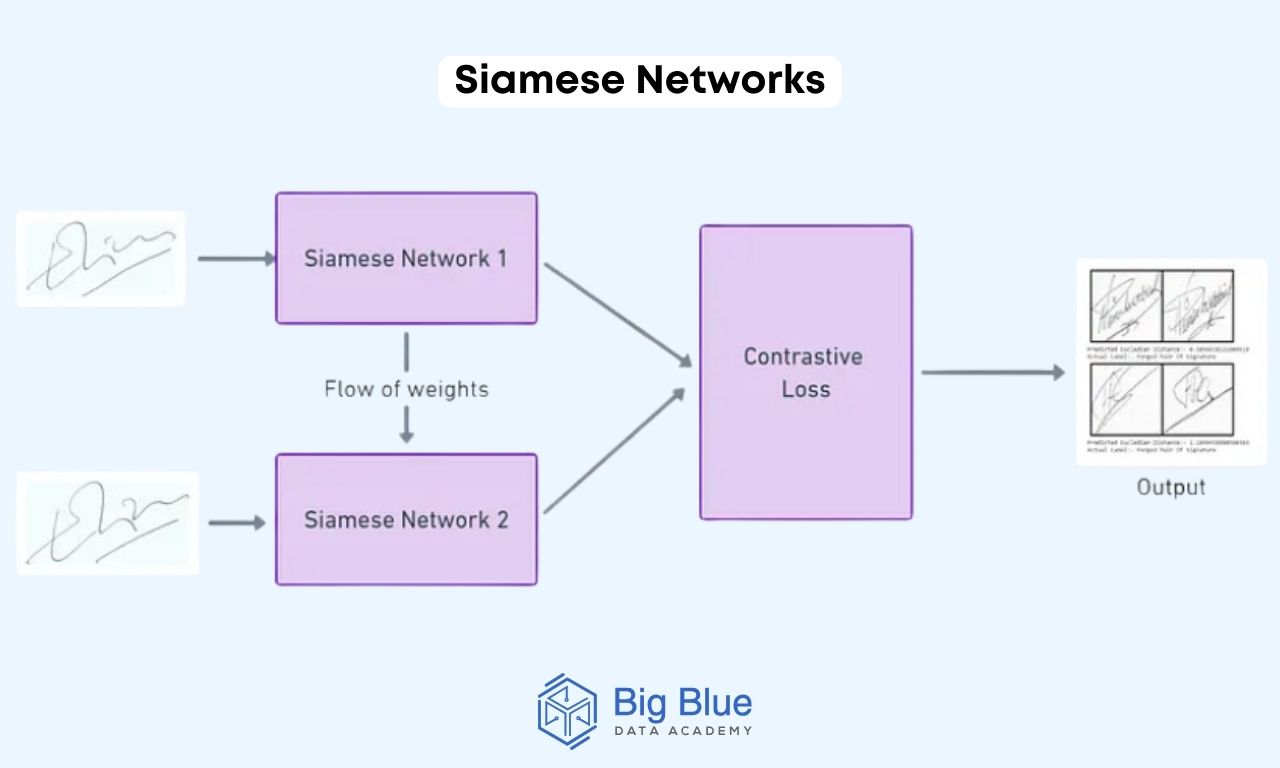
This approach is prevalent in neural network applications, particularly for face verification, image similarity, and signature verification.
Method #3: Triplet loss
Triplet loss is a deep learning loss function involving an anchor input, a positive example (similar to the anchor), and a negative example (different from the anchor).
The model is trained to minimize the distance between the anchor and the positive example while maximizing the distance between the anchor and the negative example.
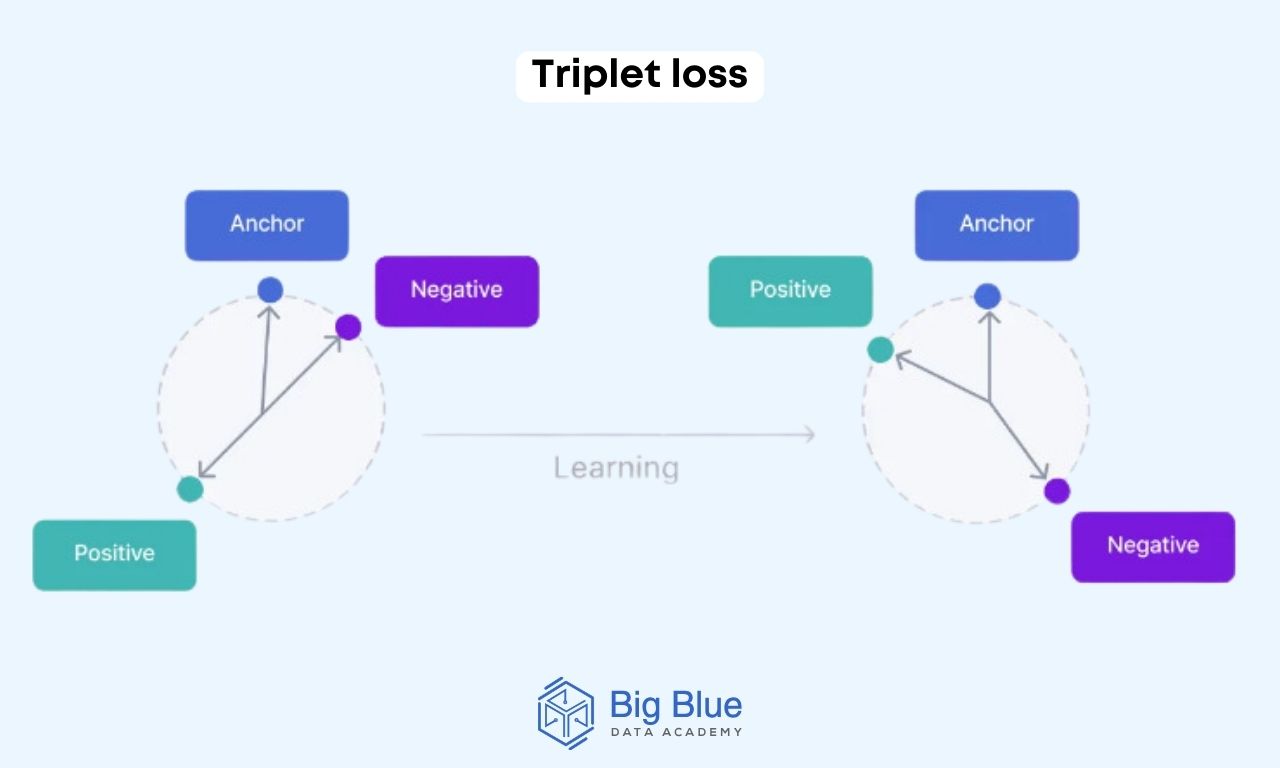
It is suitable for cases requiring differentiation between very similar data points.
Moving on, let's explore some fundamental use cases of similarity learning for a better understanding of its applications.
3 Fundamental Applications of Similarity Learning
Below we have gathered some of the fundamental applications of similarity learning for a better understanding of the range of cases it can be used.
Application #1: Face recognition
Facial recognition as we know is very important for security purposes and authentication processes.
Similarity learning is used in the various security systems for face recognition by comparing the features of a face in an image with a database of known faces.
Application #2: Product recommendations in e-commerce
Similarity learning is employed in e-commerce for product recommendations.
In essence, with the help of similarity learning, when a user views a product they like, the system can suggest alternatives or products with similar characteristics that may interest them.
Thus, the user stays longer on the platform, discovers other options that may attract them and thus strengthens the profitability of the business.
After all, this is a common tactic followed by large companies active in the field of e-commerce such as Amazon and eBay.
Application #3: Anomaly detection
Continuing, similarity learning is particularly used in the field of cyber security, but also in the financial sector to detect anomalies or extreme values in order to prevent incidents of fraud or breaches.
Furthermore, detection of anomalies with the help of similarity learning can also be carried out in the field of medicine, for example in medical imaging.
Through the comparison of medical images, medical conditions and health problems can be detected early, and thus patients may have a better course of their disease.
Ramping Up
In conclusion, we've explored what similarity learning is, how it operates, the basic methods it employs, and where it finds application.
The field of data science offers numerous opportunities for professional development and well-compensated job positions.
If you are enthusiastic and want to learn more about the field of Data Science, you can follow us for more educational posts and we will keep you posted!
.jpg)