

Similarity Learning: Ορισμός, Μέθοδοι & Εφαρμογές
Το Machine Learning φέρνει διαρκώς νέες εξελίξεις σε πληθώρα επιχειρηματικών κλάδων χάρει στα πλεονεκτήματα που προσφέρει στην λήψη στρατηγικών αποφάσεων, στην αύξηση του κέρδους και στην αντιμετώπιση του ανταγωνισμού.
Η εποπτευόμενη και η μη εποπτευόμενη μηχανική μάθηση για τις οποίες έχουμε μιλήσει εκτενώς και σε προηγούμενα άρθρα μας, είναι δύο βασικές υποκατηγορίες του machine learning που χρησιμοποιούνται για ξεχωριστούς σκοπούς η κάθε μία.
Το similarity learning (μάθηση ομοιότητας), στο οποίο θα εστιάσουμε σήμερα, είναι μια υποκατηγορία της εποπτευόμενης μάθησης το οποίο χρησιμοποιείται ευρέως σε συστήματα επαλήθευσης / αναγνώρισης προσώπου και συστάσεων.
Πιο συγκεκριμένα στο σημερινό οδηγό θα δούμε:
- Τι είναι το similarity learning
- Βασικές μεθόδους που χρησιμοποιεί
- Ορισμένες βασικές περιπτώσεις χρήσης του
Ας ξεκινήσουμε από τα βασικά.
Τι Είναι το Similarity Learning;
Το similarity learning (μάθηση ομοιότητας) αποτελεί ένα κλάδο της μηχανικής μάθησης που εστιάζει στην εκπαίδευση μοντέλων machine learning για την αναγνώριση της ομοιότητας ή ανομοιότητας ανάμεσα σε σημεία δεδομένων.
Οι αλγόριθμοι στο similarity learning αρχικά δημιουργούν μια αναπαράσταση για κάθε στοιχείο ενός συνόλου δεδομένων με τη μορφή διανύσματος (vector).
Η απόσταση μεταξύ αυτών των διανυσμάτων δείχνει το πόσο μοιάζουν τα σημεία αυτά των δεδομένων.
Έτσι όσο πιο μικρή είναι η απόσταση μεταξύ τους, τόσο μεγαλύτερη η ομοιότητά τους.
Σε αντίθεση με την πιο παραδοσιακή εποπτευόμενη μάθηση, στο similarity learning δεν απαιτεί πάντα labels (ετικέτες), αλλά ένα σημείο αναφοράς προκειμένου να εντοπίσει κατά πόσο υπάρχει ομοιότητα ή μη ανάμεσα στα στοιχεία που εξετάζονται.
Χάρει στο similarity learning, οι μηχανές μπορούν και κατανοούν καλύτερα τα διάφορα patterns, τις σχέσεις και τις δομές στα data και έτσι έχουν την δυνατότητα να προβούν αν χρειαστεί σε ανίχνευση ανωμαλιών.
Αφού είδαμε τι είναι το similarity learning, ας προχωρήσουμε στις διαφορετικές μεθόδους που χρησιμοποιεί.
Μέθοδοι Similarity Learning
Μερικές βασικές μέθοδοι στο κλάδο του similarity learning είναι οι εξής:
Μέθοδος #1: Cosine similarity (Ομοιότητα συνημιτόνου)
Το cosine similarity (ομοιότητα συνημιτόνου) μετρά την ομοιότητα μεταξύ δύο διανυσμάτων υπολογίζοντας το συνημίτονο της γωνίας μεταξύ των δύο διανυσμάτων.
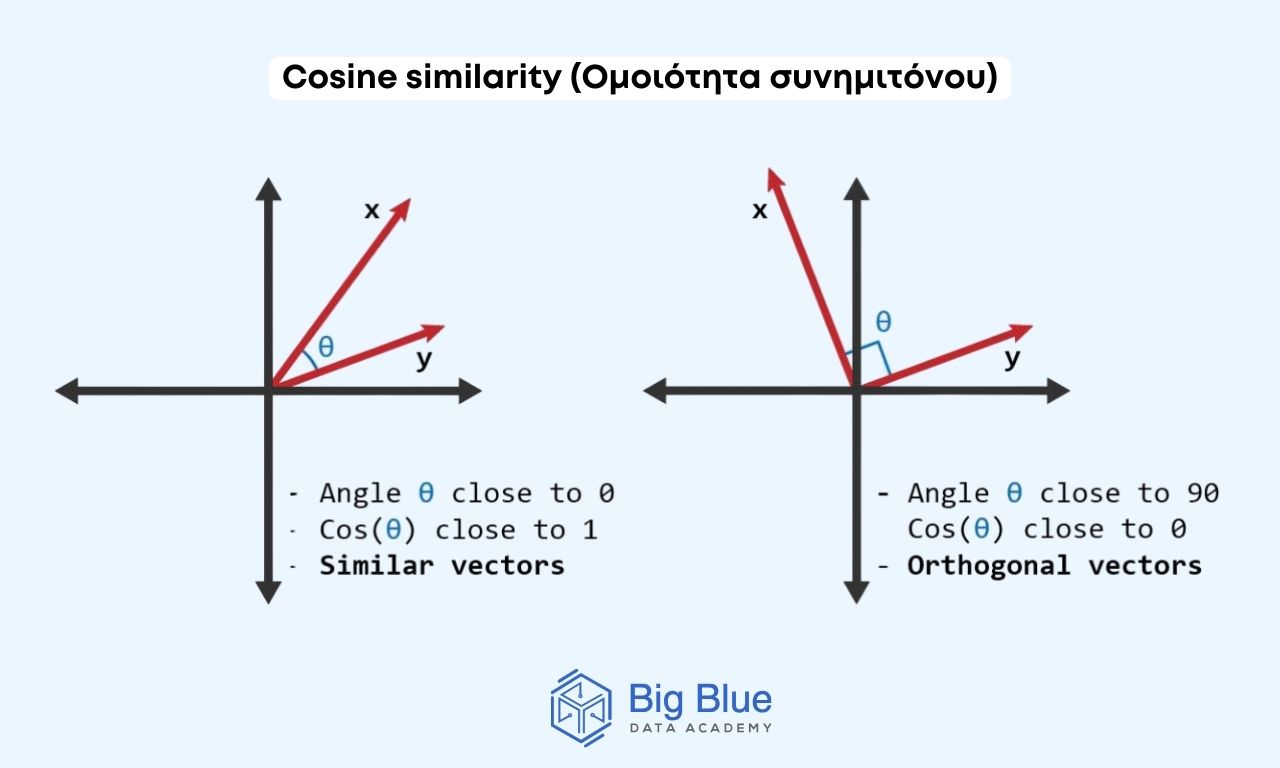
Αν το συνημίτονο είναι 1 τότε υπάρχει μέγιστη ομοιότητα, ενώ αν είναι 0 δεν υπάρχει κανένα κοινό στοιχείο ανάμεσα στα διανύσματα (vectors).
Η μέθοδος αυτή χρησιμοποιείται ευρέως ως μέτρο ομοιότητας στο χώρο της επιστήμης των δεδομένων και είναι ιδιαίτερα διαδεδομένο στο χώρο του NLP (Natural Language Processing) για την ανάλυση κειμένων και εύρεση ομοιοτήτων.
.jpg)
Μέθοδος #2: Siamese networks
Τα siamese networks (σιαμαία δίκτυα) αποτελούνται από δύο πανομοιότυπα υποδίκτυα που χρησιμοποιούν κοινά βάρη (weights).
Εκπαιδεύονται προκειμένου να παράγουν παρόμοιες αναπαραστάσεις για παρόμοια ζεύγη εισόδου και ανόμοιες αναπαραστάσεις για ανόμοια ζεύγη εισόδου.
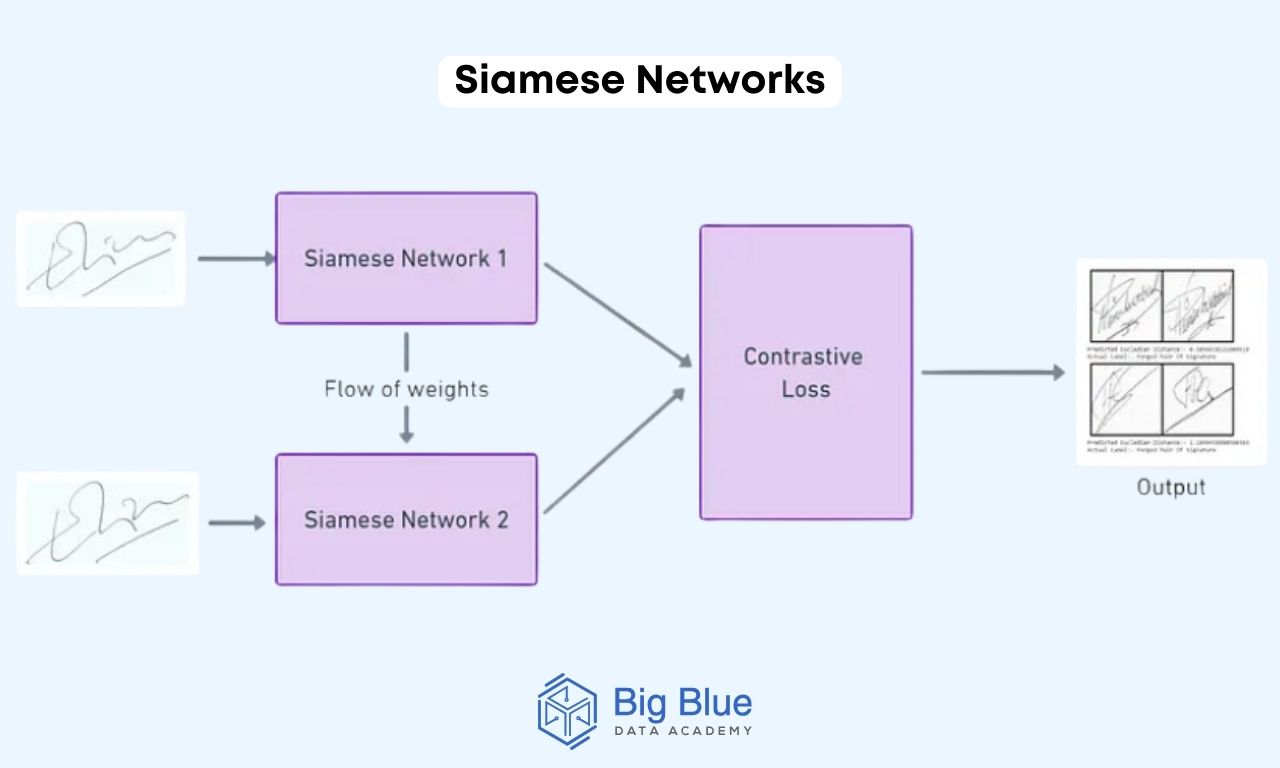
Πρόκειται για μια διαδεδομένη προσέγγιση στο τομέα των νευρωνικών δικτύων και είναι μια ιδανική μέθοδος για εργασίες επαλήθευσης προσώπου, ομοιότητας εικόνων και επαλήθευσης υπογραφής.
Μέθοδος #3: Triplet loss
Συνεχίζοντας, το triplet loss είναι μια συνάρτηση απώλειας στο deep learning που περιλαμβάνει ένα input αναφοράς (ένα anchor), ένα θετικό παράδειγμα (το οποίο είναι παρόμοιο με το anchor) και ένα αρνητικό παράδειγμα (διαφορετικό από το anchor).
Το μοντέλο εκπαιδεύεται να ελαχιστοποιεί την απόσταση μεταξύ του anchor και του θετικού παραδείγματος, ενώ μεγιστοποιεί την απόσταση μεταξύ του anchor και του αρνητικού παραδείγματος.
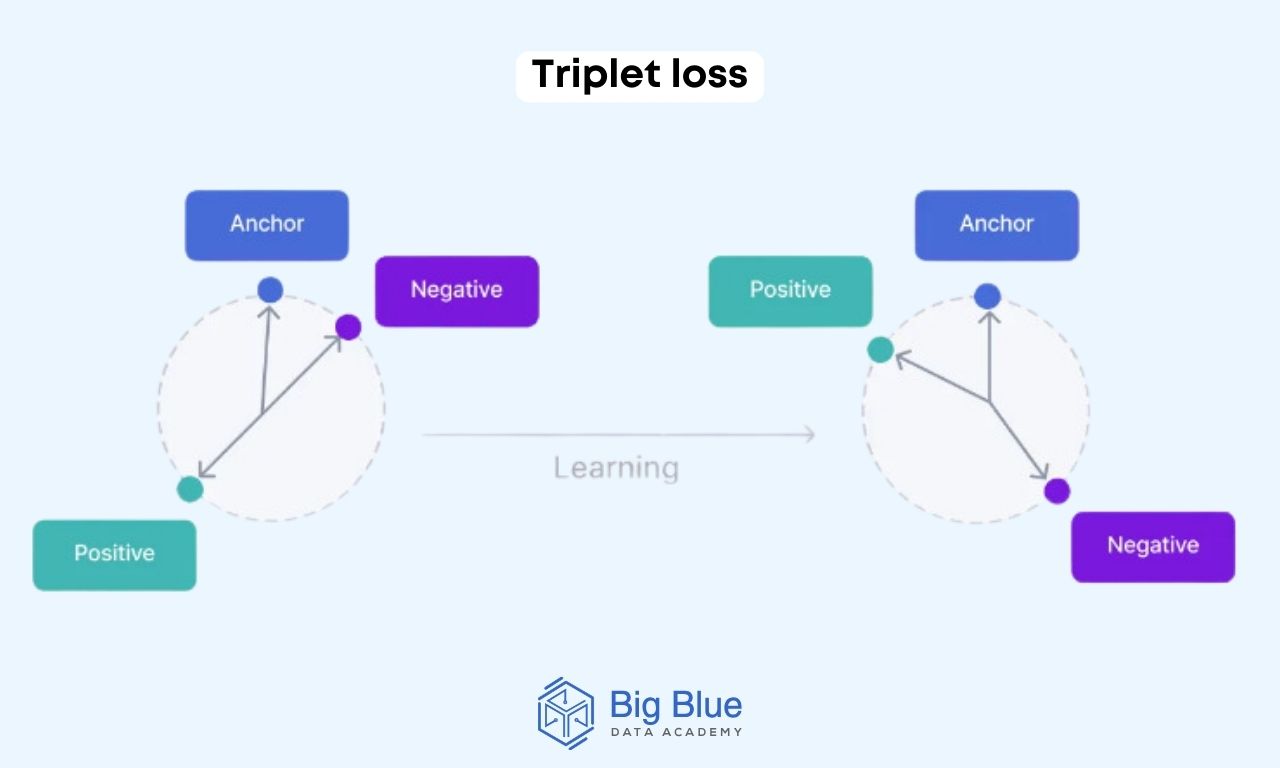
Αποτελεί ιδανική μέθοδο σε περιπτώσεις που χρειάζεται διαφοροποίηση μεταξύ πολύ παρόμοιων σημείων δεδομένων.
Συνεχίζοντας, ας δούμε ορισμένες βασικές περιπτώσεις χρήσης του similarity learning για καλύτερη κατανόηση των εφαρμογών του.
3 Βασικές Εφαρμογές Similarity Learning
Ακολούθως έχουμε συγκεντρώσει μερικές από τις βασικές εφαρμογές του similarity learning για καλύτερη κατανόηση του εύρους των περιπτώσεων που μπορεί να χρησιμοποιηθεί.
Εφαρμογή #1: Αναγνώριση προσώπου
Η αναγνώριση προσώπου όπως γνωρίζουμε είναι πολύ σημαντική για σκοπούς ασφάλειας και διαδικασίες ελέγχου ταυτότητας.
Το similarity learning χρησιμοποιείται στα διάφορα συστήματα ασφαλείας για την αναγνώριση προσώπου, συγκρίνοντας τα χαρακτηριστικά ενός προσώπου σε μια εικόνα με μια βάση δεδομένων προσώπων.
Εφαρμογή #2: Προτάσεις προϊόντων στο e-commerce
Το similarity learning χρησιμοποιείται και για προτάσεις προϊόντων στους χρήστες στο χώρο του ηλεκτρονικού εμπορίου.
Στην ουσία με τη βοήθεια του similarity learning, όταν ένας χρήστης προβάλει ένα προϊόν της αρεσκείας του, το σύστημα μπορεί να του προτείνει εναλλακτικές λύσεις ή προϊόντα με παρόμοια χαρακτηριστικά που μπορεί να τον ενδιαφέρουν.
Έτσι, ο χρήστης παραμένει περισσότερο στην πλατφόρμα, ανακαλύπτει και άλλες επιλογές που μπορεί να τον ελκύουν και έτσι ενισχύεται η κερδοφορία της επιχείρησης.
Αυτή είναι άλλωστε μια διαδεδομένη τακτική που ακολουθούν μεγάλες εταιρείες που δραστηριοποιούνται στο χώρο του ηλεκτρονικού εμπορίου όπως η Amazon και το eBay.
Εφαρμογή #3: Ανίχνευση ανωμαλιών
Συνεχίζοντας, το similarity learning χρησιμοποιείται ιδιαίτερα και στο χώρο της κυβερνοασφάλειας, αλλά και του χρηματοοικονομικού κλάδου για την ανίχνευση ανωμαλιών ή ακραίων τιμών ώστε να προληφθούν περιστατικά απάτης ή παραβιάσεων.
Ακόμη, ανίχνευση ανωμαλιών με τη βοήθεια του similarity learning μπορεί να πραγματοποιηθεί και στο χώρο της ιατρικής όπως για παράδειγμα στην ιατρική απεικόνιση (medical imaging).
Μέσα από τη σύγκριση ιατρικών εικόνων, μπορούν να ανιχνευθούν ιατρικές παθήσεις και προβλήματα υγείας έγκαιρα, και έτσι οι ασθενείς να έχουν ενδεχομένως μια καλύτερη πορεία της νόσου τους.
Με Λίγα Λόγια
Είδαμε λοιπόν τι είναι το similarity learning και πώς λειτουργεί, ποιες είναι οι βασικές μέθοδοι που χρησιμοποιεί και πού εφαρμόζεται.
Ο χώρος της επιστήμης των δεδομένων προσφέρει πολλές ευκαιρίες επαγγελματικής αποκατάστασης και θέσεων εργασίας με πολύ καλό μισθό.
Έτσι, αν αποτελεί το μονοπάτι που θέλεις να ακολουθήσεις και εσύ επαγγελματικά, πάρε μέρος στο Data Science Bootcamp της Big Blue, για να λάβεις όλα τα απαραίτητα εφοδια και ουσιαστική πρακτική γνώση από την πρώτη κιόλας μέρα!
.jpg)