

Synthetic Data: Definition, Benefits & Examples (2023)
Organizations and businesses quite often, due to limitations, deficiencies, and the emerging need for sustainability more than ever, use synthetic data instead of real data, owing to the advantages and the multitude of use cases that can be applied.
In today's article, we will therefore explore:
What synthetic data is
What advantages it offers
Some examples and use cases
Let’s begin with a basic definition.
What is Synthetic Data?
Synthetic data refers to data that is artificially generated using algorithms, models, or statistical techniques to replicate various properties, distributions, and relationships found in real data.
Essentially, synthetic data somehow mimics the characteristics and patterns of real data but does not originate from actual observations.
One of the primary purposes driving the production of synthetic data is to create a substitute for real data in cases where the use of real data is not feasible or appropriate.
Next, we will proceed to analyze the main advantages that synthetic data offers.
Main Advantages of Synthetic Data
The use of synthetic data is steadily gaining ground and wide acceptance as it can provide several benefits compared to real-world data.
In fact, Gartner predicted that by 2030, most of the data used in artificial intelligence will be generated synthetically through rules, statistical models, simulations, or other techniques.
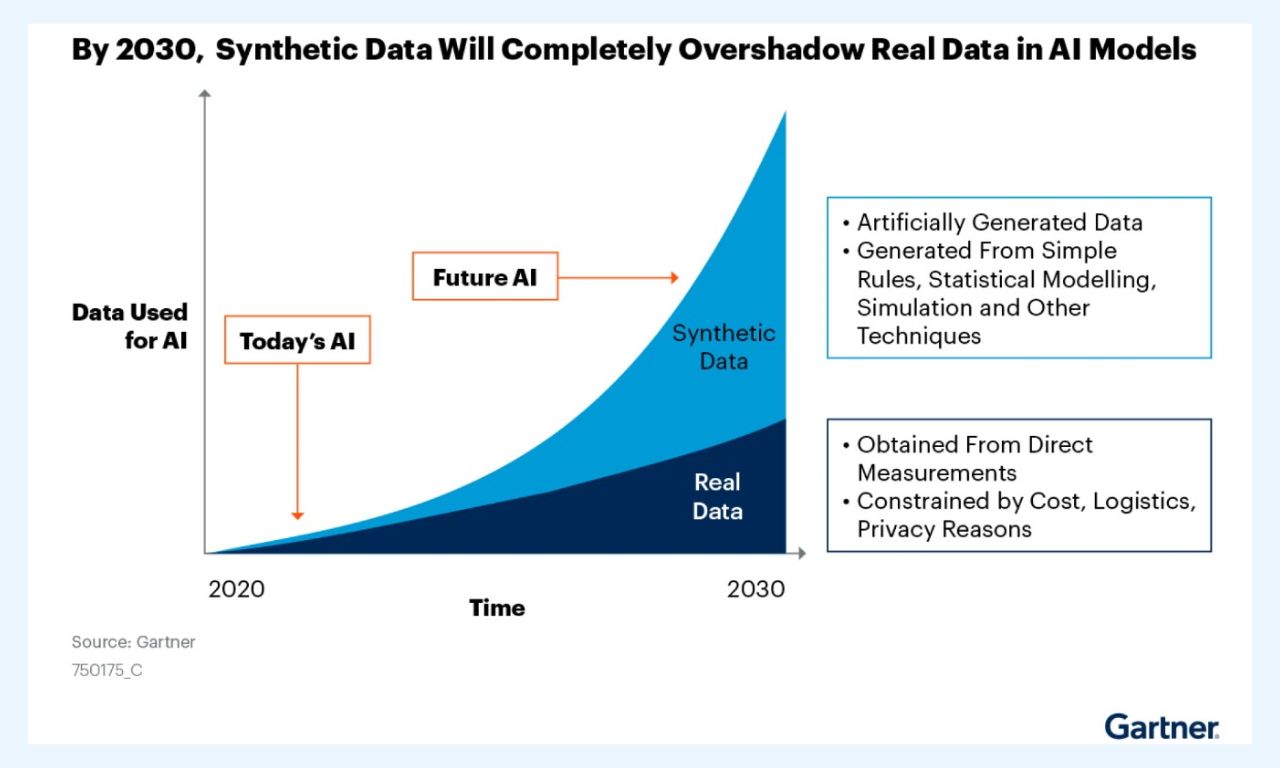
Some of the key advantages offered by synthetic data include:
Cost and Time Efficiency
Synthetic data serves as a cost-effective alternative to real-world data.
This is because it reduces the need for extensive data collection, cleaning, and curation efforts, saving both time and resources.
Moreover, using synthetic data, a dataset can be generated in a shorter time frame with the right software and technology.
Enhanced Security
Synthetic data allows organizations to share or work with data without exposing sensitive information, thus ensuring compliance with privacy regulations.
Furthermore, synthetic data enables testing and experimentation without risks and potential negative consequences on real systems, environments, or users.
This feature makes synthetic data suitable for use in healthcare and the pharmaceutical industry, especially when dealing with sensitive health and personal data.
Greater Flexibility
An organization or business can tailor synthetic data to specific needs, customizing the data for particular conditions that cannot be observed with authentic data.
For instance, a company can create datasets for software testing and quality assurance (QA) purposes for DevOps teams.
Where is Synthetic Data Used?
The primary application of synthetic data is in training neural networks and machine learning models.
Data scientists and developers of these models require carefully labeled large datasets. Synthetic data fulfills this need.
The performance of AI models is enhanced by synthetic training data, which eliminates random biases and provides new insights.
Additionally, synthetic data can be used to protect user privacy and comply with privacy laws, especially in cases involving sensitive health and personal data.
Below, we have gathered some use cases:
Use Case #1: Healthcare
Synthetic data is extensively used in the healthcare sector to create synthetic medical images (such as MRI and CT scans) for training machine learning models in disease diagnosis.
Synthetic health records are also used for testing electronic health record systems without exposing real patient data.
Use Case #2: Financial Fraud Detection
Continuing, the creation of synthetic financial transaction data for training fraud detection algorithms can ensure that various sensitive customer information remains confidential.
Another use case involves simulating market data for testing trading algorithms without the risks associated with real financial markets.
Use Case #3: Natural Language Processing (NLP)
Additionally, a third use case is natural language processing (NLP).
Synthetic text data is often generated to train chatbots and sentiment analysis models.
In Summary
We have seen what synthetic data is, why it is important, and some use cases.
In summary, collecting high-quality data from the real world is often challenging, expensive, and time-consuming.
Synthetic data offers a solution to this problem.
The field of data science is continually evolving, and new opportunities for development and innovative solutions are emerging.
If you are intrigued and want to learn more about data science in general, follow us for more educational articles and we will keep you updated!
.jpg)