

7 Ερωτήσεις Συνέντευξης για Θέση Machine Learning (με Απαντήσεις)
Αν βρίσκεσαι στα πρώτα σου βήματα στον τομέα του machine learning και θέλεις να ενημερωθείς για πιθανές ερωτήσεις που μπορούν να σου κάνουν σε μια συνέντευξη για δουλειά τότε αυτός ο οδηγός είναι για εσένα.
Στο σημερινό άρθρο έχουμε συγκεντρώσει 7 βασικές ερωτήσεις που μπορεί να σου κάνουν αναφορικά με το machine learning, για να είσαι κατάλληλα προετοιμασμένος και να αυξήσεις τι πιθανότητες να προσληφθείς.
Ας ξεκινήσουμε με την πρώτη ερώτηση.
Ερώτηση #1 : Ποιες Είναι οι Διαφορές Ανάμεσα στο Deep Learning και το Machine Learning;
Μια βασική ερώτηση που μπορούν να σου κάνουν στη συνέντευξη για machine learning δεν είναι φυσικά άλλη από τις διαφορές ανάμεσα στο deep learning και το machine learning.
Ας δούμε μια ενδεικτική απάντηση.
Απάντηση:
Η βαθιά μάθηση (deep learning) επιτρέπει στις μηχανές να λαμβάνουν διάφορες επιχειρηματικές αποφάσεις χρησιμοποιώντας τεχνητά νευρωνικά δίκτυα (artificial neural networks), για αυτό και χρειάζεται τεράστιο όγκο δεδομένων για εκπαίδευση.
Με απλά λόγια, οι υπολογιστές μαθαίνουν να επεξεργάζονται δεδομένα με τρόπο εμπνευσμένο από τον ανθρώπινο εγκέφαλο.
Τα μοντέλα βαθιάς μάθησης μπορούν να αναγνωρίσουν σύνθετα και πολύπλοκα μοτίβα σε εικόνες, κείμενο, ήχους κ.α. για να παράγουν προβλέψεις με ακρίβεια.
Η μηχανική μάθηση (machine learning) είναι ένα παρακλάδι της τεχνητής νοημοσύνης που δίνει στις μηχανές τη δυνατότητα να λαμβάνουν επιχειρηματικές αποφάσεις χωρίς εξωτερική βοήθεια, χρησιμοποιώντας τις γνώσεις που αποκτήθηκαν από προηγούμενα δεδομένα.
Οι υπολογιστές μέσω του machine learning, μαθαινουν να αναγνωρίζουν μοτίβα στα δεδομένα και σιγά σιγά να γίνονται ανεξάρτητοι.
Επίσης, αναφορικά με την επίλυση προβλημάτων, υπάρχει διαφορετική προσέγγιση.
Στο machine learning, ο αλγόριθμος παίρνει το πρόβλημα, το σπάει σε μικρότερα κομμάτια και επιλύει το κάθε ένα ξεχωριστά.
Αντίθετα στο deep learning, ο αλγόριθμος λαμβάνει ένα πρόβλημα και αμέσως παρέχει την λύση.
Ερώτηση #2: Ποιες Είναι οι Διαφορές μεταξύ Εποπτευόμενης και μη Εποπτευόμενης Μηχανικής Μάθησης;
Απάντηση:
Στην εποπτευόμενη μάθηση, οι αλγόριθμοι χρησιμοποιούν επισημασμένα σύνολα δεδομένων για να εκπαιδευτούν, όπου κάθε σημείο δεδομένων σχετίζεται με έναν στόχο ή μια ετικέτα (label).
Τα μοντέλα λαμβάνουν άμεση ανατροφοδότηση για να επιβεβαιώσουν εάν η έξοδος που προβλέπεται είναι σωστή.
Στην εποπτευόμενη μάθηση, ο αλγόριθμος εκπαιδεύεται σε ένα επισημασμένο σύνολο δεδομένων, όπου κάθε σημείο δεδομένων σχετίζεται με έναν στόχο ή μια ετικέτα.
Κύριος στόχος είναι να εκπαιδευτεί το μοντέλο να προβλέπει την έξοδο κατά τη λήψη νέων δεδομένων.
Αντίθετα, στην μη εποπτευόμενη μάθηση, οι αλγόριθμοι χρησιμοποιούν δεδομένα χωρίς ετικέτα.
Ο αλγόριθμος προσπαθεί να βρει μοτίβα, δομές ή σχέσεις μέσα στα δεδομένα χωρίς την καθοδήγηση των επισημασμένων εξόδων.
Στη μάθηση χωρίς επίβλεψη τα αποτελέσματα είναι συγκριτικά λιγότερο ακριβή με την εποπτευόμενη μάθηση.
Bonus point: Φυσικά, σε αυτό το σημείο μπορείς να αναφέρεις και την ημι-εποπτευόμενη μάθηση που αποτελεί έναν συνδυασμό εποπτευόμενης και μη εποπτευόμενης μάθησης, και χρησιμοποιείται όταν έχουμε ένα πολύ μικρό σύνολο δεδομένων με ετικέτα και ένα μεγάλο σύνολο δεδομένων χωρίς ετικέτα.
Στην ουσία, ο αλγόριθμος εκπαιδεύεται σε ένα μείγμα επισημασμένων και μη επισημασμένων δεδομένων.
Ερώτηση #3: Πώς Διαφοροποιείται η Ταξινόμηση από την Παλινδρόμηση στο Machine Learning
Απάντηση:
Οι αλγόριθμοι παλινδρόμησης και ταξινόμησης είναι αλγόριθμοι εποπτευόμενης μάθησης.
Και οι δύο αλγόριθμοι χρησιμοποιούνται για την πραγματοποίηση προβλέψεων στη μηχανική μάθηση και λειτουργούν με επισημασμένα σύνολα δεδομένων.
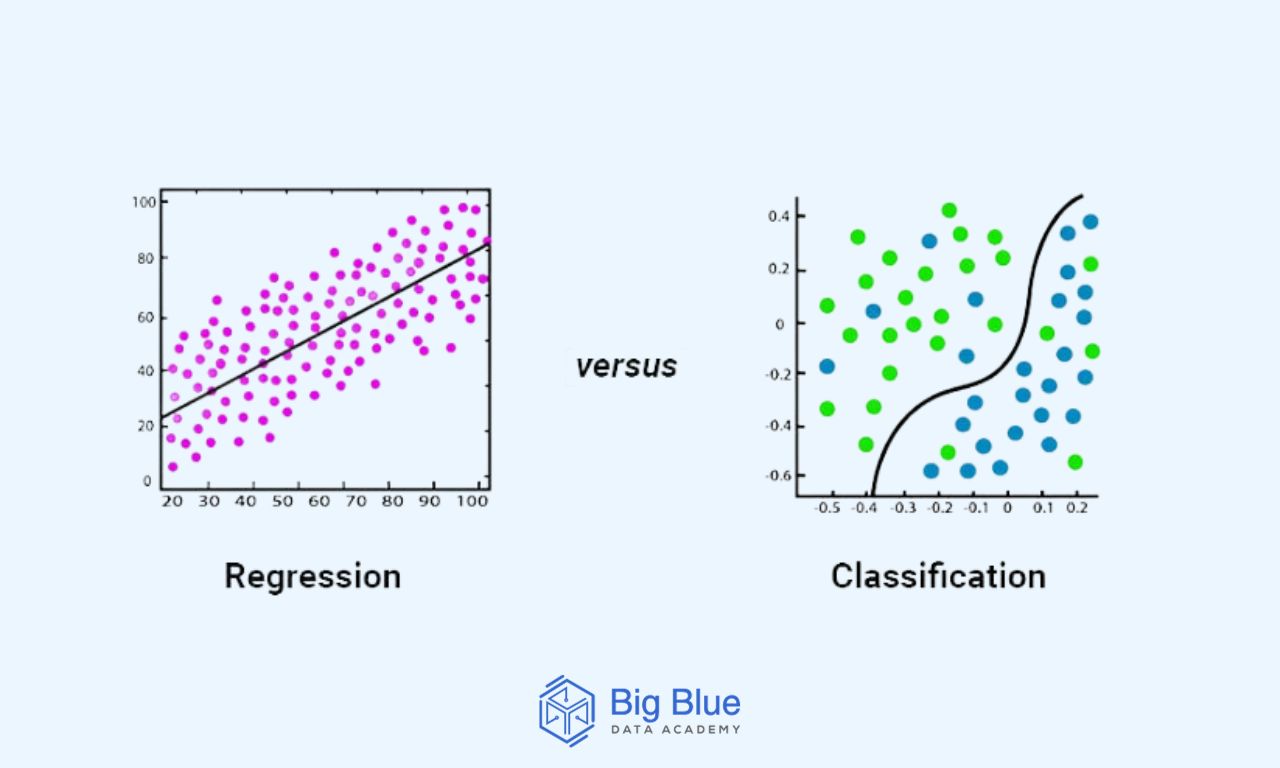
Η κύρια διαφορά μεταξύ των αλγορίθμων παλινδρόμησης και ταξινόμησης έγκειται στο ότι οι αλγόριθμοι παλινδρόμησης (regression algorithms) χρησιμοποιούνται για την πρόβλεψη των συνεχών τιμών όπως η τιμή και η ηλικία.
Αντίθετα, οι αλγόριθμοι ταξινόμησης (classification algorithms) χρησιμοποιούνται για την πρόβλεψη/ταξινόμηση των διακριτών τιμών όπως αληθές ή ψευδές, αρσενικό/θηλυκό κ.α.
Ερώτηση #4 : Τι Ορίζουμε ως Δέντρα Αποφάσεων
Απάντηση:
Τα δέντρα αποφάσεων (decision trees) είναι ένας τύπος εποπτευόμενου αλγορίθμου μάθησης που μπορεί να χρησιμοποιηθεί τόσο για προβλήματα ταξινόμησης όσο και παλινδρόμησης.
Όπως υποδηλώνει και το όνομά τους, πρόκειται για δομές που μοιάζουν με δέντρα όπου ο κάθε εσωτερικός κόμβος αντιπροσωπεύει ένα χαρακτηριστικό, τα κλαδιά αντιπροσωπεύουν τους κανόνες απόφασης και ο κάθε κόμβος φύλλων αντιπροσωπεύει το αποτέλεσμα.
Τα δέντρα αποφάσεων είναι γνωστά για την ευκολία κατανόησής τους, διαθέτουν ευελιξία και μπορούν να χρησιμοποιηθούν για επίλυση διαφόρων προβλημάτων.
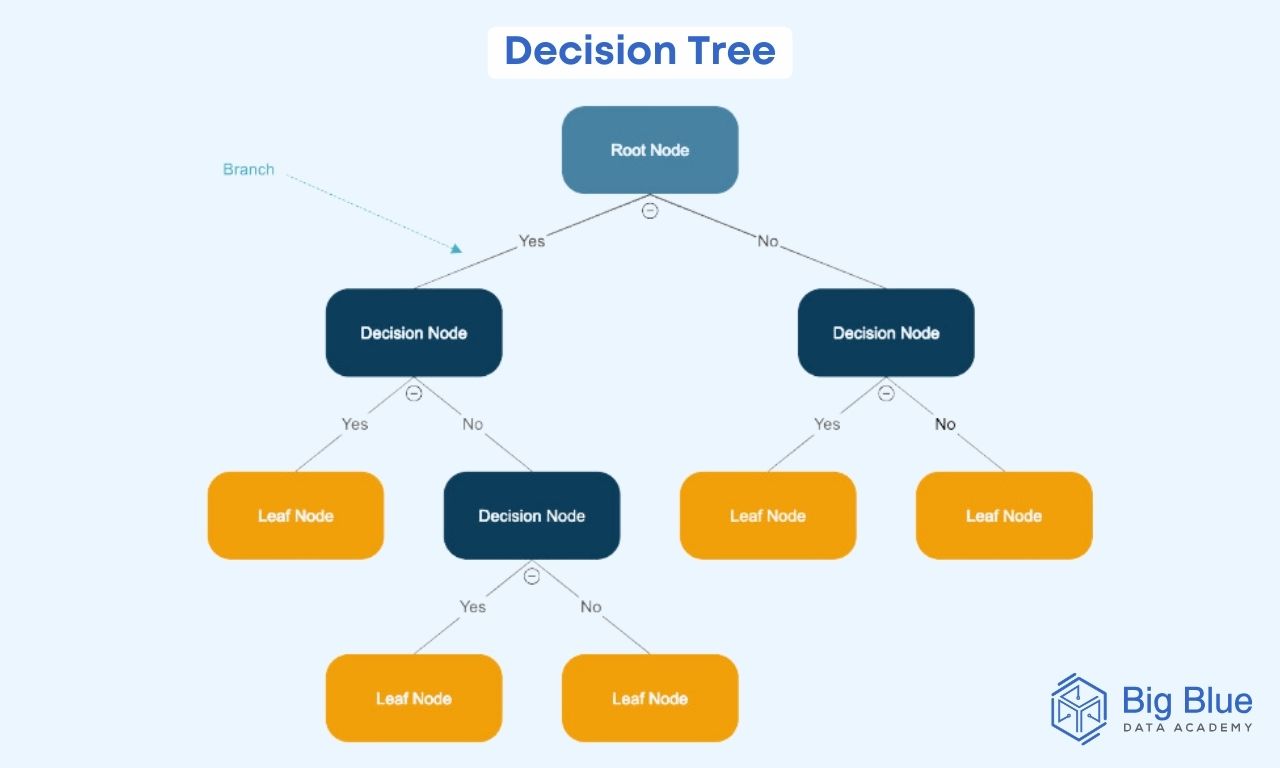
Ακόμη, τα δέντρα αποφάσεων μπορούν να διαχειριστούν τόσο κατηγορικά όσο και αριθμητικά δεδομένα.
Σε ένα δέντρο αποφάσεων, ο ριζικός κόμβος (γνωστός και ως γονικός κόμβος) αντιπροσωπεύει ολόκληρο το σύνολο δεδομένων, το οποίο διαιρείται σε δύο ή περισσότερα ομοιογενή σύνολα.
Οι κόμβοι φύλλων είναι οι τελικοί κόμβοι εξόδου (γνωστοί και ως θυγατρικοί κόμβοι) και το δέντρο δεν μπορεί να διαχωριστεί περαιτέρω μετά την επίτευξη ενός κόμβου φύλλων.
Ερώτηση #5: Ποια Είναι η Διαφορά Μεταξύ του K-Means και του Αλγορίθμου KNN;
Απάντηση:
Ο αλγόριθμος K-Means είναι ένας μη εποπτευόμενος αλγόριθμος μηχανικής μάθησης που χρησιμοποιείται για σκοπούς συσταδοποίησης (clustering).
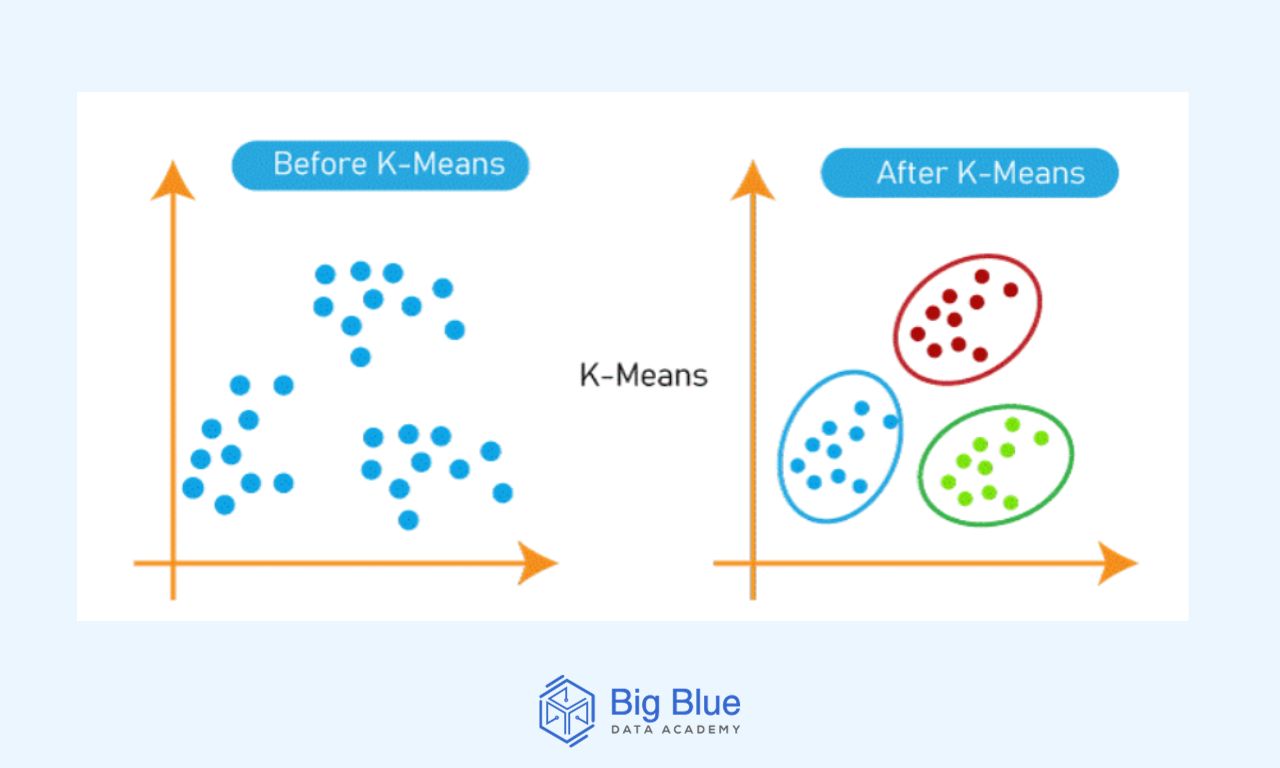
Ο αλγόριθμος K-Means βοηθά στην επισήμανση δεδομένων σχηματίζοντας clusters μέσα σε ένα σύνολο δεδομένων με βάση τον μέσο όρο των αποστάσεων μεταξύ διακριτών σημείων.
Από την άλλη πλευρά, ο KNN είναι ένας εποπτευόμενος, μη παραμετρικός αλγόριθμος μηχανικής μάθησης και χρησιμοποιείται γενικά για την εργασία ταξινόμησης και παλινδρόμησης.
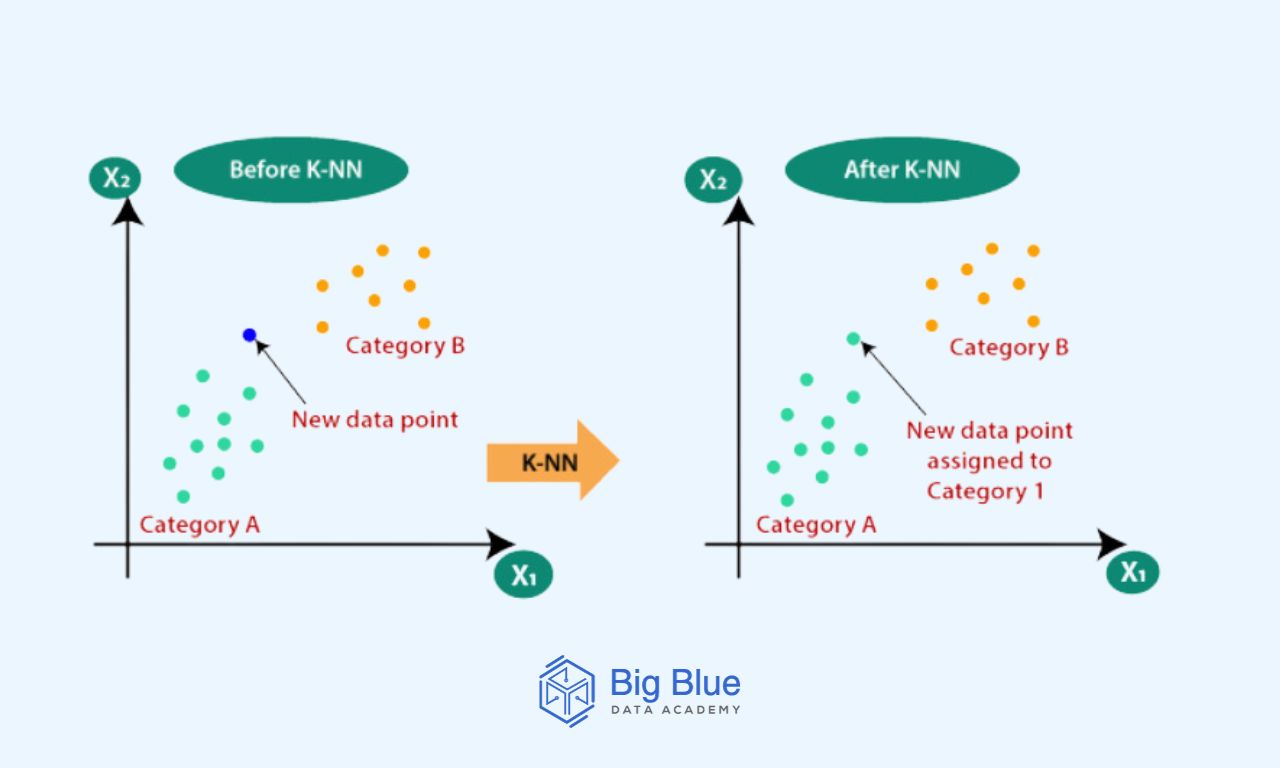
Ο KNN (k-nearest neighbors algorithm) χρησιμοποιεί την εγγύτητα για να κάνει ταξινόμηση ετικετών ή πραγματοποίηση προβλέψεων σχετικά με την ομαδοποίηση ενός μεμονωμένου σημείου δεδομένων.
Ερώτηση #6: Ποιες Είναι Ορισμένες Μέθοδοι για το Χειρισμό Τιμών που Λείπουν σε ένα Σύνολο Δεδομένων
Μια ακόμη ερώτηση που μπορούν να σου κάνουν αφορά το χειρισμό των missing values σε ένα σύνολο δεδομένων.
Απάντηση:
Το συγκεκριμένο πρόβλημα θεωρείται ως μία από τις μεγάλες προκλήσεις που αντιμετωπίζουν όσοι εργάζονται στον κλάδο του data science.
Ορισμένες από τις συνήθεις μεθόδους χειρισμού τιμών που λείπουν είναι οι εξής:
- Η διαγραφή των συγκεκριμένων σειρών
- Η αντικατάσταση με mean/median/mode
- Η πρόβλεψη των τιμών που λείπουν
- Η χρήση αλγορίθμων που υποστηρίζουν τιμές που λείπουν
Ερώτηση #7: Τι Είναι το Overfitting στη Μηχανική Μάθηση και Πώς Μπορεί να Αποφευχθεί;
Απάντηση:
Το overfitting συμβαίνει όταν το μοντέλο μηχανικής μάθησης παρέχει ακριβείς προβλέψεις για δεδομένα εκπαίδευσης, αλλά όχι για νέα δεδομένα.
Όταν οι data scientists χρησιμοποιούν μοντέλα machine learning για να πραγματοποιήσουν προβλέψεις, εκπαιδεύουν αρχικά το μοντέλο σε ένα γνωστό σύνολο δεδομένων.
Έπειτα με βάση αυτές τις πληροφορίες, το μοντέλο προσπαθεί να προβλέψει τα αποτελέσματα για νέα σύνολα δεδομένων.
Το overfitting συμβαίνει για διάφορους λόγους, όπως:
- Το μέγεθος των δεδομένων εκπαίδευσης είναι πολύ μικρό και δεν περιέχει αρκετά δείγματα δεδομένων για να αντιπροσωπεύει με ακρίβεια όλες τις πιθανές τιμές δεδομένων εισόδου.
- Τα δεδομένα εκπαίδευσης περιέχουν μεγάλες ποσότητες άσχετων πληροφοριών
- Το μοντέλο εκπαιδεύεται για πολύ μεγάλο χρονικό διάστημα σε ένα ενιαίο σύνολο δειγμάτων δεδομένων
Το overfitting μπορεί να αποφευχθεί χρησιμοποιώντας ένα μεγάλο όγκο δεδομένων.
Όμως, αν έχουμε μια μικρή βάση δεδομένων και κατά συνέπεια χρειαστεί να δημιουργήσουμε ένα μοντέλο βασισμένο σε αυτό, τότε μπορούμε να χρησιμοποιήσουμε μια γνωστή τεχνική που ονομάζεται cross-validation.
Σε αυτή τη μέθοδο, σε ένα μοντέλο δίνεται συνήθως ένα σύνολο από data γνωστών δεδομένων στο οποίο εκτελείται ένα σύνολο δεδομένων εκπαίδευσης και ένα σύνολο data άγνωστων δεδομένων απέναντι στα οποία δοκιμάζεται το μοντέλο μας.
Το βασικό μέλημα της μεθόδου αυτής είναι να οριστεί ένα σύνολο δεδομένων για τη «δοκιμή» του μοντέλου κατά τη φάση της εκπαίδευσής του.
Με Λίγα Λόγια
Είδαμε, λοιπόν, 7 βασικές ερωτήσεις συνέντευξης για machine learning, αλλά και τις απαντήσεις που ταιριάζουν στην κάθε μια.
Με αυτόν τον τρόπο, ένας data scientist μπορεί να έχει μια καλύτερη εικόνα για τις ερωτήσεις που μπορεί να του κανουν και έτσι να προετοιμαστεί ακόμα καλύτερα για μια ενδεχόμενη συνέντευξη.
Αν, λοιπόν, θέλεις να γίνεις επαγγελματίας data scientist, να λάβεις ουσιαστική πρακτική γνώση και να εξελίξεις την καριέρα σου, τότε πάρε μέρος στο Data Science Bootcamp και εξασφάλισε την θέση σου στην αγορά εργασίας!
.jpg)