

6 Data Engineer Interview Questions (With Answers)
If you're at the beginning of your professional career as a data engineer and wondering how to be adequately prepared for your upcoming job interview, then today's article is for you.
In this guide, we've gathered 6 essential questions that might be asked about your role as a data engineer, so you can be well-informed and able to respond systematically.
Let's start with the first question on our list.
Question #1: What is Hadoop and What Are Its Key Features?
A fundamental question you may encounter is about the Hadoop tool.
Let's see how you could answer:
Answer:
Apache Hadoop is an open-source software framework that provides the ability to manage large data sets.
Hadoop is an extremely valuable tool for a data engineer, as it offers a scalable solution for storing and processing structured and unstructured data.
Its main advantage is the ease of providing ample storage space for data and a vast amount of processing power to manage numerous tasks concurrently.
Some of its core components include:
HDFS (Hadoop Distributed File System): It is the primary data storage system in Hadoop, designed for managing big data and providing high fault tolerance.
Hadoop Common: This comprises a set of libraries and utilities used by the Hadoop application.
Hadoop YARN: YARN is used for resource management in the Hadoop cluster, scheduling, and coordinating job execution.
Hadoop MapReduce: It is an algorithm that divides big data processing tasks into smaller tasks and then distributes them across different nodes for execution.
Question #2: What Is Data Modeling?
Data modeling is the initial step in designing a database by a data engineer and analyzing data.
Here's a sample response.
Answer:
Data modeling is the process of creating a conceptual representation of data structures and the relationships between them.
It is an integral part of the database design process.
By modeling data, we simplify the documentation of data types, improve data organization and utilization, reduce the risk of errors in data, save time, and create opportunities for optimizing business processes.
Data is represented in the form of entities, attributes, and relationships.
There are three categories of data models, based on the level of abstraction, which include:
- Conceptual data models
- Logical data models
- Physical data models
Question #3: What Is the Difference Between Structured and Unstructured Data?
Data engineers are often required to transform unstructured data into structured data for data analysis using various transformation methods.
Let's explore the differences between them:
Answer:
Structured data consists of predefined data types with specific patterns that make it easy to search.
On the other hand, unstructured data is information that is not organized according to a predetermined data model or format and, therefore, cannot be stored in a traditional relational database.
Structured data is often stored in data warehouses, while unstructured data is stored in data lakes.
Question #4: What Is the Difference Between a Data Warehouse and an Operational Database?
Answer:
A data warehouse is a centralized repository of structured data that has been processed and modeled for business purposes. The system of a data warehouse deals with historical data and is designed for loading high and complex queries.
It also supports multiple concurrent users and is built to retrieve large volumes of data.
Operational database management systems, on the other hand, are used for managing dynamic sets of data in real-time.
They support high-volume transaction processing for thousands of concurrent users.
Question #5: Which Python Libraries Are Most Effective for Data Processing?
Answer:
The most popular Python libraries for data processing are pandas and NumPy. Additionally, for parallel processing of large datasets, libraries like Dask, PySpark, and Datatable can be used.
The choice of the appropriate library depends on the specific needs and requirements of the data at hand.
Question #6: What Is the Star Schema and the Snowflake Schema?
Answer:
A star schema is a database schema used for storing data in a star-like structure. This schema consists of a central fact table and several directly connected dimension tables.
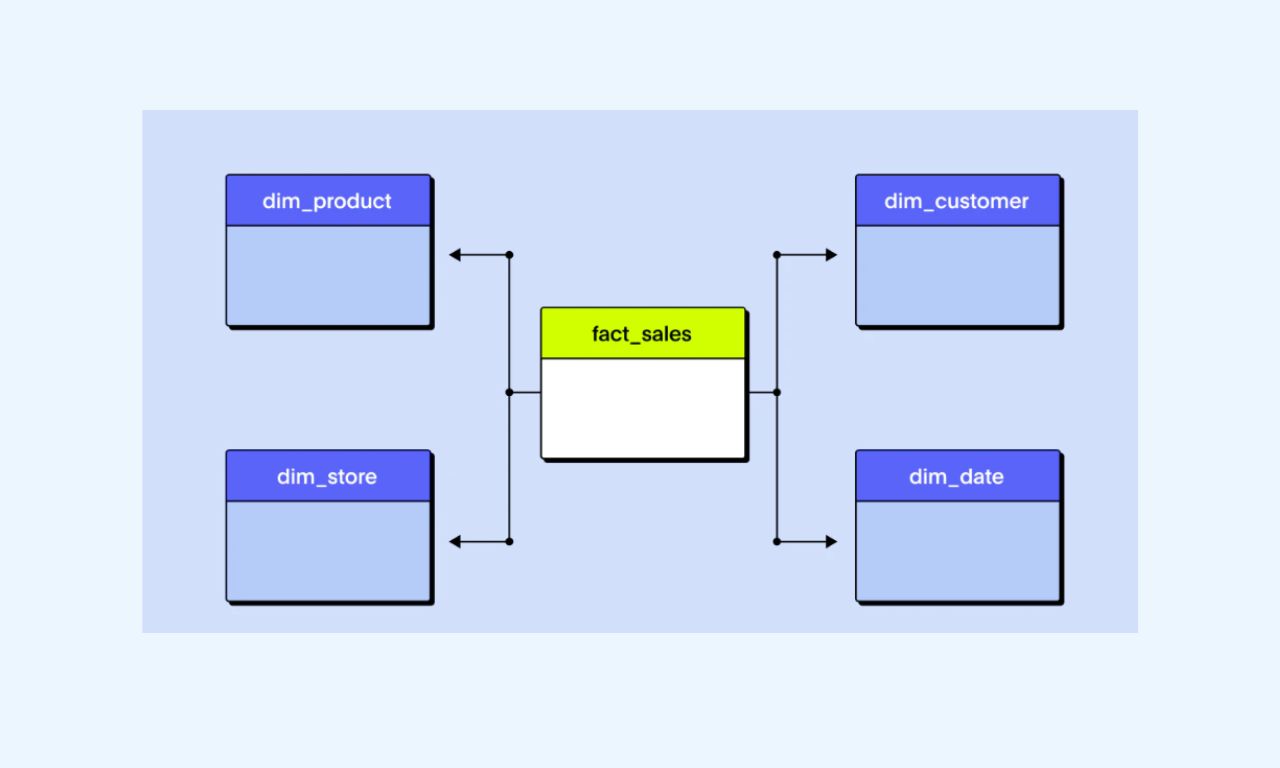
The data modeling in a star schema is the simplest type of data warehousing schema and is ideal for querying large datasets.
The fact table contains information related to measurements, while dimension tables contain information about descriptive attributes.
On the other hand, the Snowflake schema is an extension of the Star Schema and gets its name because it further divides data, creating a more normalized structure.
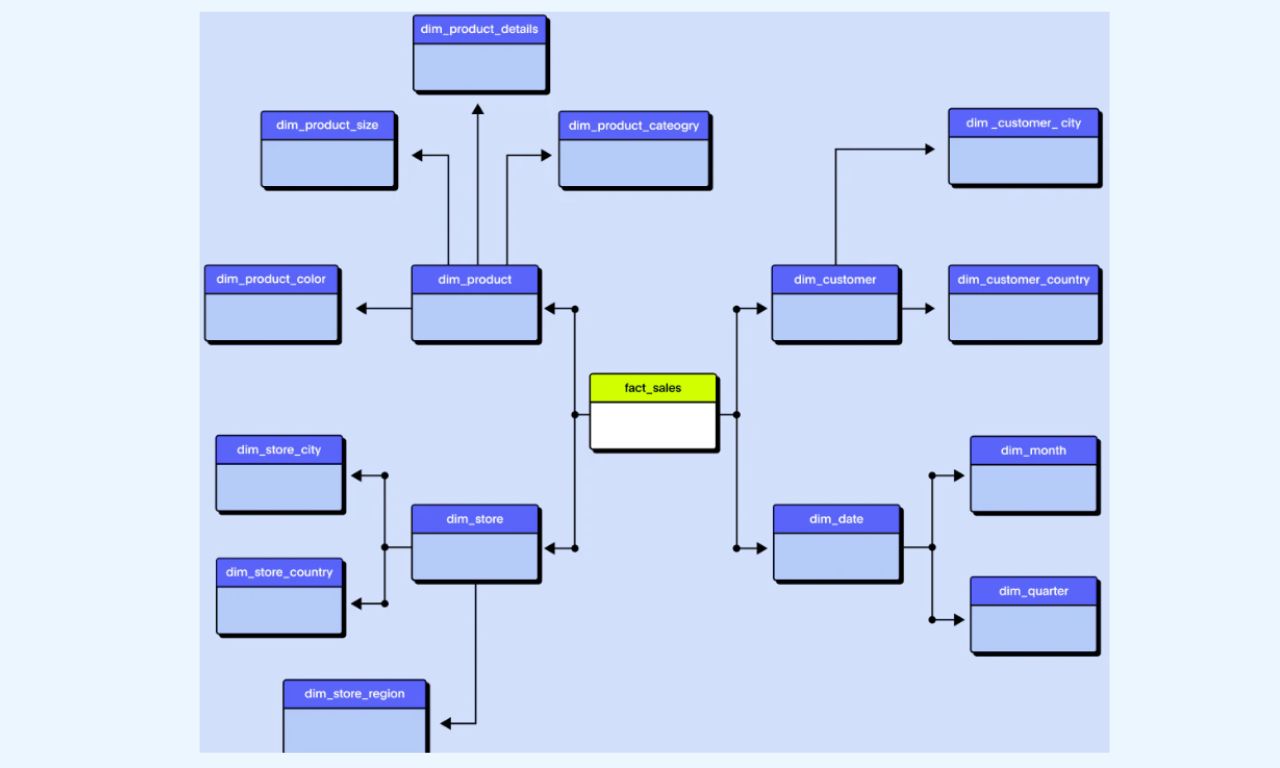
In the Snowflake schema, dimensions are normalized into sub-dimensions, making the structure more normalized.
Normalization can save storage space but may lead to less desirable performance for analytical queries.
Rumping Up
We've covered 6 fundamental interview questions for the position of a data engineer along with suitable answers.
This way, a data engineer can have a better understanding of the questions they might be asked during their next job interview and be adequately prepared.
If you are intrigued and want to learn more about data engineering, follow us and we will keep you updated with more educational articles!
.jpg)