

6 Ερωτήσεις Συνέντευξης για Data Engineer (με Απαντήσεις)
Αν βρίσκεσαι στην αρχή της επαγγελματικής σου καριέρας ως data engineer και αναρωτιέσαι πώς μπορείς να είσαι κατάλληλα προετοιμασμένος για την επόμενή σου συνέντευξη για δουλεία, τότε το σημερινό άρθρο είναι για σένα.
Στο σημερινό οδηγό έχουμε συγκεντρώσει 6 βασικές και σημαντικές ερωτήσεις που μπορούν να σου κάνουν σχετικά με το ρόλο σου ως data engineer, προκειμένου να είσαι κατάλληλα ενημερωμένος και να είσαι σε θέση να απαντήσεις μεθοδικά.
Ας ξεκινήσουμε με την πρώτη ερώτηση στην λίστα μας.
Ερώτηση #1: Τι Είναι το Hadoop και Ποια Είναι τα Βασικά του Χαρακτηριστικά;
Μια βασική ερώτηση που μπορούν να σου κάνουν είναι για το εργαλείο Hadoop.
Ας δούμε πώς θα μπορούσες να απαντήσεις.
Απάντηση:
Το Apache Hadoop είναι ένα framework λογισμικού ανοιχτού κώδικα που παρέχει τη δυνατότητα διαχείρισης μεγάλων συνόλων δεδομένων.
Το Hadoop είναι ένα ιδιαίτερα χρήσιμο εργαλείο για έναν data engineer, καθώς αποτελεί μια επεκτάσιμη λύση για αποθήκευση και επεξεργασία δομημένων αλλά και μη δομημένων δεδομένων (unstructured data).
Το κύριο πλεονέκτημα που το διακρίνει είναι η εύκολη παροχή του τεράστιου χώρου ο οποίος χρειάζεται για την αποθήκευση δεδομένων αλλά και μιας τεράστιας ποσότητας επεξεργαστικής ισχύος για τη διαχείριση απεριόριστων εργασιών ταυτόχρονα.
Μερικά από τα δομικά του στοιχεία είναι τα ακόλουθα:
HDFS: Το κατανεμημένο σύστημα αρχείων Hadoop αποτελεί το βασικό σύστημα αποθήκευσης δεδομένων με δυνατότητα διαχείρισης big data, παρέχοντας υψηλή ανοχή σε σφάλματα.
Hadoop Common: Είναι ένα σύνολο βιβλιοθηκών και βοηθητικών προγραμμάτων που χρησιμοποιούνται συνήθως από την εφαρμογή Hadoop.
Hadoop YARN: Χρησιμοποιείται για τη διαχείριση πόρων συμπλέγματος που προγραμματίζει και συντονίζει τους χρόνους εκτέλεσης στις εφαρμογές.
Hadoop MapReduce: Πρόκειται για έναν αλγόριθμο που χωρίζει τις εργασίες επεξεργασίας big data σε πιο μικρές και έπειτα τις κατανέμει σε διαφορετικούς κόμβους, πριν μεταβεί στην εκτέλεσή τους.
Ερώτηση #2: Τι Είναι η Μοντελοποίηση Δεδομένων;
Η μοντελοποίηση δεδομένων αποτελεί το αρχικό βήμα για το σχεδιασμό της βάσης δεδομένων από έναν data engineer και την ανάλυση των δεδομένων.
Ας δούμε μια ενδεικτική απάντηση.
Απάντηση:
Η μοντελοποίηση δεδομένων (data modeling) είναι η διαδικασία δημιουργίας μιας εννοιολογικής αναπαράστασης των δομών δεδομένων (data structures), αλλά και των μεταξύ τους σχέσεων.
Όπως προαναφέραμε, αποτελεί αναπόσπαστο κομμάτι στη διαδικασία σχεδιασμού βάσεων δεδομένων.
Μοντελοποιώντας τα δεδομένα, απλοποιείται η τεκμηρίωση των τύπων δεδομένων που διαθέτουμε, πραγματοποιείται καλύτερη οργάνωση και διευθέτηση του τρόπου με τον οποίο τα χρησιμοποιούνται τα δεδομένα.
Ακόμη, μειώνεται ο κίνδυνος σφαλμάτων στα δεδομένα, εξοικονομείται χρόνος και παρουσιάζονται ευκαιρίες για τη βελτιστοποίηση των επιχειρηματικών διαδικασιών.
Τα δεδομένα αναπαρίστανται με τη μορφή οντοτήτων, χαρακτηριστικών και σχέσεων.
Υπάρχουν 3 κατηγορίες μοντέλων δεδομένων, ανάλογα με το βαθμό αφαίρεσης.
Αυτά είναι τα ακόλουθα:
- Τα εννοιολογικά μοντέλα δεδομένων
- Τα λογικά μοντέλα δεδομένων
- Τα φυσικά μοντέλα δεδομένων
Ερώτηση #3: Ποια Είναι η Διαφορά Μεταξύ Δομημένων και μη Δομημένων Δεδομένων
Οι data engineers συχνά καλούνται να μετατρέψουν τα μη δομημένα δεδομένα (unstructured data) σε δομημένα δεδομένα (structured data) για ανάλυση δεδομένων, χρησιμοποιώντας διαφορετικές μεθόδους μετασχηματισμού.
Ακολούθως, ας δούμε πώς διαφοροποιούνται μεταξύ τους.
Απάντηση:
Τα δομημένα δεδομένα αποτελούνται από καθορισμένους τύπους δεδομένων με συγκεκριμένα μοτίβα (patterns) που τα καθιστούν εύκολα αναζητήσιμα.
Από την άλλη πλευρά, τα μη δομημένα δεδομένα είναι πληροφορίες που δεν είναι οργανωμένες σύμφωνα με ένα προκαθορισμένο μοντέλο δεδομένων ή μορφή και συνεπώς δεν μπορούν να αποθηκευτούν σε μια παραδοσιακή σχεσιακή βάση δεδομένων.
Τα δομημένα δεδομένα αποθηκεύονται συχνά σε data warehouses, ενώ τα μη δομημένα δεδομένα αποθηκεύονται σε data lakes.
Ερώτηση #4: Ποια Είναι η Διαφορά Ανάμεσα σε ένα Data Warehouse και σε ένα Operational Database
Απάντηση:
Μια αποθήκη δεδομένων (data warehouse) αποτελεί ένα κεντρικό αποθετήριο δομημένων δεδομένων που έχουν υποβληθεί σε επεξεργασία και μοντελοποίηση για κάποιο επιχειρηματικό σκοπό.
Το σύστημα ενός data warehouse ασχολείται με ιστορικά δεδομένα και έχει σχεδιαστεί για τη φόρτωση υψηλών και σύνθετων ερωτημάτων.
Ακόμη, υποστηρίζει μερικούς ταυτόχρονους χρήστες και έχει δημιουργηθεί για να ανακτά μεγάλους όγκους δεδομένων.
Τα λειτουργικά συστήματα διαχείρισης βάσεων δεδομένων (Online Transactions Processing Databases) χρησιμοποιούνται για τη διαχείριση δυναμικών συνόλων δεδομένων σε πραγματικό χρόνο.
Υποστηρίζουν επεξεργασία συναλλαγών μεγάλου όγκου για χιλιάδες ταυτόχρονους πελάτες.
Ερώτηση #5: Ποιες Βιβλιοθήκες Python Είναι πιο Αποτελεσματικές για Επεξεργασία Δεδομένων;
Απάντηση:
Οι πιο δημοφιλείς βιβλιοθήκες της Python για την επεξεργασία δεδομένων είναι τα libraries pandas και Numpy.
Βέβαια, για παράλληλη επεξεργασία μεγάλων συνόλων δεδομένων, μπορούμε να χρησιμοποιήσουμε βιβλιοθήκες όπως Dask, Pyspark και Datatable.
Επομένως, η κατάλληλη βιβλιοθήκη υποδεικνύεται με βάση τις ανάγκες και απαιτήσεις των εκάστοτε δεδομένων.
Ερώτηση #6: Τι Είναι το Star Schema και το SnowFlake Schema
Απάντηση:
Ένα σχήμα αστεριού (Star Schema) είναι ένα σχήμα βάσης δεδομένων που χρησιμοποιείται για την αποθήκευση δεδομένων σε μορφή αστεριού.
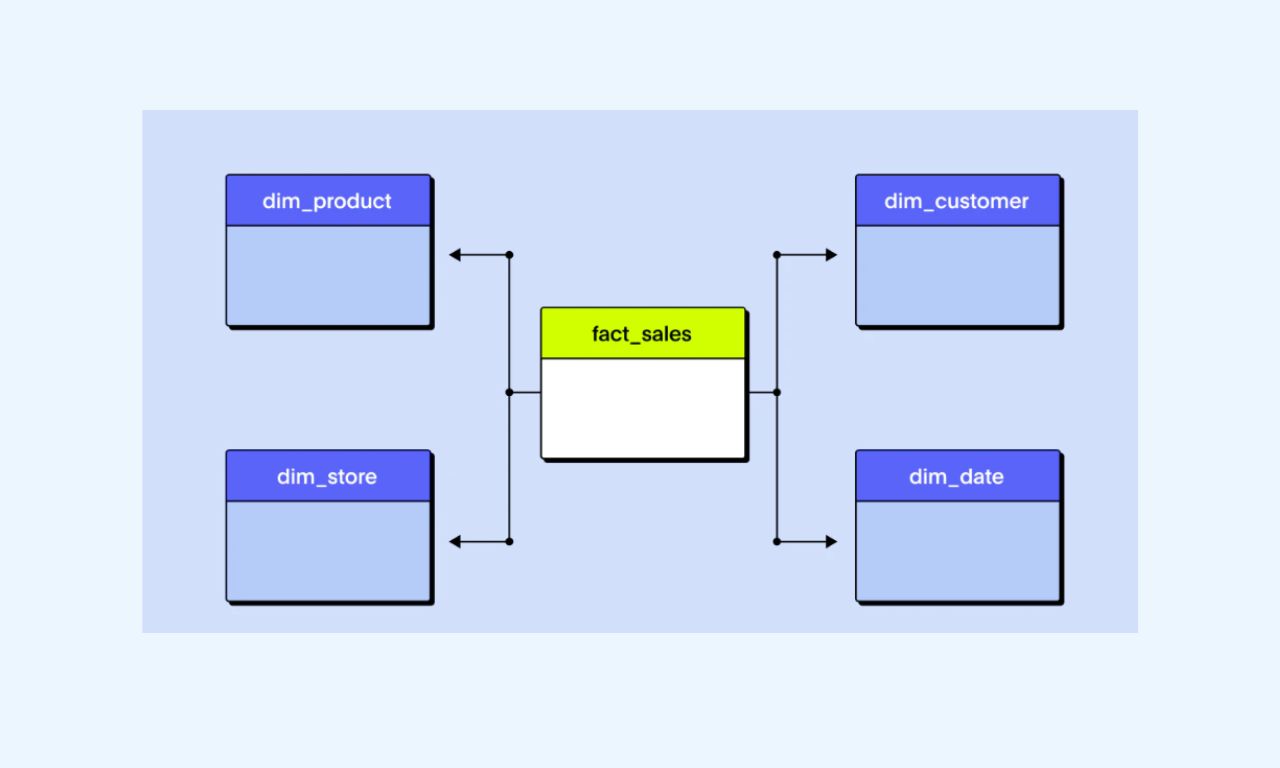
Το συγκεκριμένο schema αποτελείται από έναν κεντρικό πίνακα, που ονομάζεται πίνακας γεγονότων (fact table), και έναν αριθμό άμεσα συνδεδεμένων άλλων πινάκων, που ονομάζονται πίνακες διαστάσεων (dimension tables).
Το μοντέλο δεδομένων Star Schema είναι ο απλούστερος τύπος σχήματος αποθήκης δεδομένων και είναι ιδανικό για την υποβολή ερωτημάτων σε μεγάλα σύνολα δεδομένων.
Ο πίνακας πληροφοριών περιλαμβάνει πληροφορίες σχετικά με μετρήσεις, ενώ οι πίνακες ιδιοτήτων περιέχουν πληροφορίες σχετικά με περιγραφικά χαρακτηριστικά.
Από την άλλη πλευρά, το Snowflake Schema αποτελεί μια επέκταση του Star Schema, και ως προς την δομή του μοιάζει με snowflake, δηλαδή χιονονιφάδα, καθώς δημιουργεί επιπλέον δεδομένα, διαιρώντας περαιτέρω τα δεδομένα.
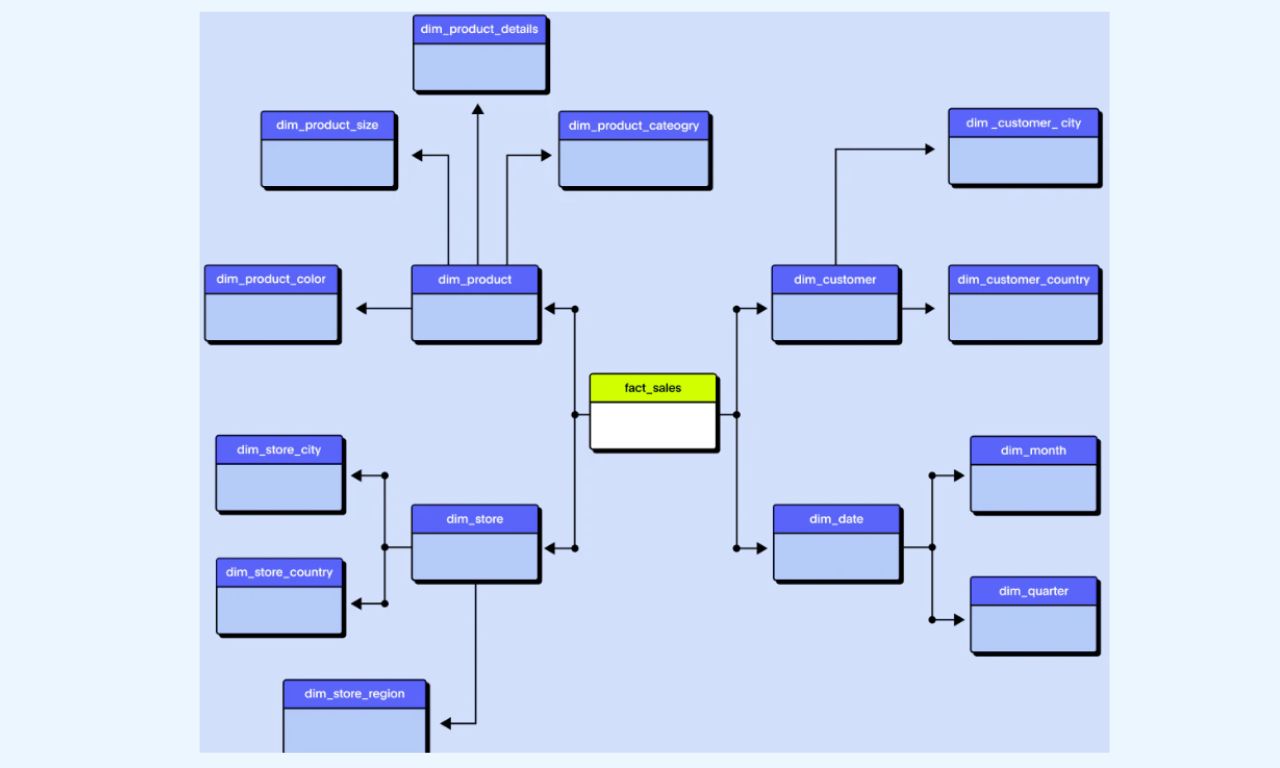
Στο snowflake schema, οι διαστάσεις (dimensions) υποδιαιρούνται σε υποδιαστάσεις (sub-dimensions), κάνοντας έτσι τη δομή πιο κανονικοποιημένη.
Με τη σειρά της, η κανονικοποίηση μπορεί να οδηγήσει σε λιγότερη επιθυμητή απόδοση για αναλυτικές ερωτήσεις, αλλά μπορεί να εξοικονομήσει χώρο αποθήκευσης.
Με Λίγα Λόγια
Είδαμε, λοιπόν, 6 βασικές ερωτήσεις συνέντευξης για τη θέση του data engineer, αλλά και τις απαντήσεις που ταιριάζουν κατάλληλα στην κάθε μια.
Με αυτόν τον τρόπο, ένας data engineer μπορεί να έχει μια καλύτερη εικόνα για τις ερωτήσεις που ενδέχεται να του κανουν στην επόμενη συνέντευξη για δουλεία ώστε να είναι κατάλληλα προετοιμασμένος.
Αν, λοιπόν, θέλεις να γίνεις επαγγελματίας data engineer, να λάβεις ουσιαστική πρακτική γνώση και να απογειώσεις την καριέρα σου, τότε πάρε μέρος στο Data Engineering Bootcamp και εξασφάλισε την θέση σου στην αγορά εργασίας!
.jpg)